
In this 26th article for SQL Server Always On Availability Groups series, we will discuss the process to suspend and resume data movements between AG replicas.
Requirements
We can configure SQL Server Always On Availability Groups in the Synchronized and Asynchronized commit mode depending upon application criticality, accepted data loss, disaster recovery, network bandwidth.
Suppose we need to reboot the servers to apply OS patches, SQL patches, scheduled activities, OS related issues. Usually, we follow this order to avoid any automatic failover:
- Reboot the secondary replica first
- AG failover
- Reboot the secondary replica (old primary replica)
In the synchronous commit, the primary replica waits for the acknowledgment from the secondary replica to commit it on the primary. If we stop the SQL Services on the secondary replica, SQL Server immediately changes the synchronization to Asynchronous mode. Once the secondary replica establishes a connection, data synchronization becomes synchronous commit. While we follow the sequence to reboot the servers, it might cause distribution in data synchronization.
Consider another case where you have implemented a two replica synchronous data commit. Your both servers are in different sites, and your network team informed that there would be a network outage or slowness in network connectivity between both the sites. One way to remediate data synchronization is that you change the mode to asynchronous. In this way, the primary replica does not wait for acknowledgment from the secondary. However, in the network fluctuations, you might get packet drops that might cause issues with your secondary replica synchronization.
In this article, we find answers to the following questions:
- Can we suspend the data movement from primary to the secondary replica?
- Can we suspend data movement for a specific secondary replica in case we have multiple secondary replicas?
- What is the impact on a primary replica in case you suspend data movement?
- How to resume data movement from the primary to the secondary replica?
Prerequisites
You should go through earlier articles (ToC at the bottom) and configure the two or more nodes SQL Server Always On Availability Group.
In this article, we use the following two-node AG replica.
- Primary replica: SQLNode2\INST1
- Secondary replica: SQLNode1\INST1
- AG database: SQLShackDemo
Suspend data movements in SQL Server Always On Availability Groups
SQL Server Always On has two kinds of replicas – Primary and Secondary. A primary replica is suitable for both read-only and writes transactions. The secondary replica can be configured to allow read-only connections, but we cannot write data into it until it takes over the role of a primary replica after failover. Data movement happens from the primary to the secondary replica.
We can suspend this data movement from both the primary and secondary replica. We can also use SSMS GUI, t-SQL, or PowerShell script for this purpose.
Suspend data movement from the primary replica in SQL Server Always On Availability Groups
If we connect to the primary SQL instance and stop data movement, it stops data movement for all connected secondary replicas. SQL Server allows us to 5 synchronous replicas (1 primary and 4 secondaries). We cannot stop data movement for a specific secondary replica from the primary SQL Instance. Once we stop data movement, the primary replica works well and available for the client connections. In case you use readable secondary, your existing connections works along with the new connections.
Suspend data movement from the secondary replica in SQL Server Always On Availability Groups
We can suspend data movement for a specific secondary replica as well. For this requirement, you need to connect the corresponding SQL instance and stop data movement. If we suspend data movement for a specific secondary replica (in case of multiple secondary replicas), it does not impact other replicas, and they continue receiving the data regularly. The local secondary replica database shows status NOT SYNCHRONIZING. In the case of readable secondary, it does not allow new connections, but the existing connection works.
How to suspend data movement in SQL Server Always On Availability Groups
The process to suspend data movement is the same from primary and secondary replica; however, you need to be connected to the appropriate instance.
Connect to the SQL in SSMS, navigate to Always On Availability Groups-> Availability Groups-> Availability Databases.

Right-click on the database for which we want to suspend the data movement.

Alternatively, you can run the following t-SQL to suspend data movement for the [SQLShackDemo] database.
|
1 2 |
ALTER DATABASE [SQLShackdemo] SET HADR SUSPEND; GO |
It puts a pause symbol in front of the database to show that data movement is stopped.

If you suspend data movement from the primary replica and check the status from the secondary replica, it shows a red-cross mark.

In the AG dashboard, you get warning and errors because databases are not synchronized.

Impact of suspend data synchronization on the primary replica database
Usually, in a standalone database, SQL Server truncates the log after the log backup. In the synchronous availability group, it also truncates the log on the checkpoint during the log backup as it commits data first at the secondary replica.
Now, if we have paused data synchronization, the primary replica database continues to hold the transaction logs. It won’t truncate the logs despite you take regular transaction log backups. It might fill up your transaction log and cause low disk space issues. Therefore, you should not suspend data movement for a longer duration, especially in the case of a highly OLTP environment. However, if you still get the transaction log full issue, you should consider adding disk space, resume or remove the availability group database.
Resume data movement in SQL Server Always On Availability Groups
To resume the data movement from the primary to the secondary replica, right-click on the availability group database and click on the Resume Data Movement.

Alternatively, you can run the following t-SQL script as well.
|
1 2 |
ALTER DATABASE [SQLShackdemo] SET HADR RESUME; GO |
If we had suspended data movement from the primary, you should resume as well from the primary. It resumes data movements for all secondary replicas. However, if we had suspended data movement locally from the secondary instance, you must resume it from the secondary instance. It captures all pending transaction logs and changes the database status to Synchronized\Synchronizing as per your configuration. Your secondary database works in the asynchronous data commit until it has altogether in sync with the primary.
It logs the events in the SQL Server error logs as well. In the below screenshot, we see a few highlighted logs about the suspend, resume, and recovery LSN.

Monitor suspend and resume data movement using dynamic management views
We can utilize dynamic management views to monitor data movement from the primary to the secondary replica.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT ar.replica_server_name, adc.database_name, ag.name AS ag_name, dhdrs.synchronization_state_desc, dhdrs.is_commit_participant, dhdrs.last_sent_lsn, dhdrs.last_sent_time, dhdrs.last_received_lsn, dhdrs.last_hardened_lsn, dhdrs.last_redone_time FROM sys.dm_hadr_database_replica_states AS dhdrs INNER JOIN sys.availability_databases_cluster AS adc ON dhdrs.group_id = adc.group_id AND dhdrs.group_database_id = adc.group_database_id INNER JOIN sys.availability_groups AS ag ON ag.group_id = dhdrs.group_id INNER JOIN sys.availability_replicas AS ar ON dhdrs.group_id = ar.group_id AND dhdrs.replica_id = ar.replica_id where database_name='SQLShackDemo' |
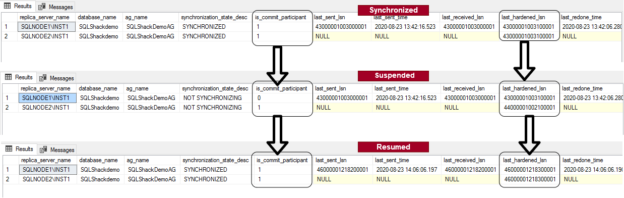
In the below output, we captured the LSN and commit participant details in the following scenario.
-
In the first part, the database is a synchronized state in both replicas
- It shows value 1 for the is_commit_participant column. It shows that we have synchronized commit mode and both replica participating in the data commit
- We see the same LSN value in the last_hardended_lsn in both primary and secondary replica. It is also equal to last_sent_lsn in the SQLNode\INST1 instance
-
In the second image, we captured the same output after suspending data movement between primary and secondary replica
- Since the secondary replica is not participating in commit (suspended state), you can see value 0 for the secondary replica SQLNode\INST1. It shows that even we have configured synchronous data commit but this time, AG working as an asynchronous commit
- We can see the difference in the last_hardened_lsn of both replicas. In the suspended state, the secondary replica cannot receive the transaction blocks; therefore, it does not apply any logs on the secondary database
-
In the third image, we capture the data after resuming data movement
- It again marks the is_commit_participant value to 1 because the secondary replica again gets a synchronized status
- It again matches the last_hardened_lsn for both replicas

Conclusion
In this article, we explored the suspend and resume data movements in SQL Server Always On Availability Groups. You must resume the data movement once your work completes, so that transaction log growth is in control of the primary replica database.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023