

This article will cover testing or verification aspects of Type 2 Slowly Changing Dimensions in a Data Warehouse.
Introduction
As we discussed in a previous article, Implementing Slowly Changing Dimensions (SCDs) in Data Warehouses, there are three main types of slowly changing dimensions, such as Type 1, Type 2, and Type 3. Out of these Type 1 is the simple dimension where you will simply maintain only the latest version of the attribute. For example, if the employee got promoted to Senior Software Engineer from Software Engineer, you will simply overwrite the existing value to the new value so that the historical aspect is lost.
Type 2 Slowly Changing Dimensions are used to track historical data in a data warehouse. This is the most common approach in dimension. This article uses a sample database of AdventureworksDW which is the sample database for the data warehouse.
Following is the schema of the DimEmployee dimension table in the AdventureworksDW database.
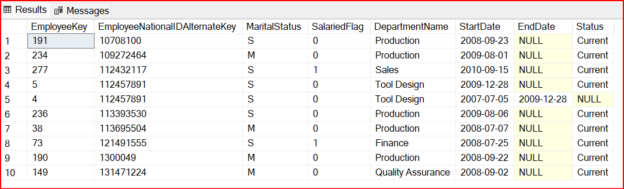
The following figure shows the sample dataset for Type 2 Slowly Changing Dimensions.
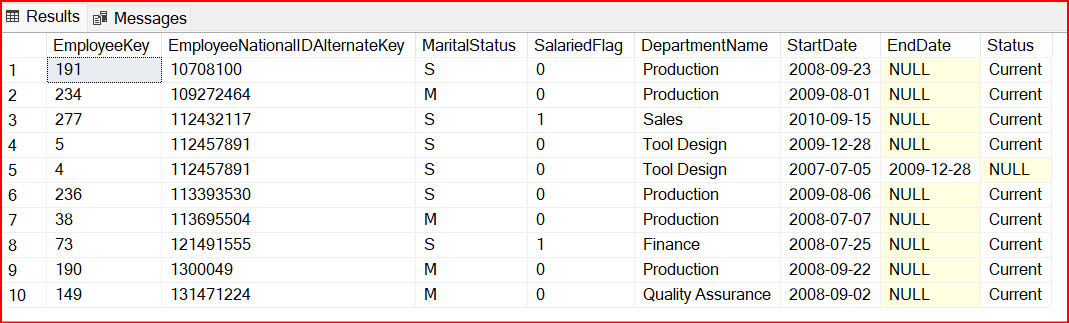
If you further examine record number 4 and 5, you will observe that it is the same employee who has two records. This is due to the fact any attribute has changed and to track the historical data, in type 2 Slowly Changing Dimensions, the new record is added with the status current, and the previous record is set to NULL.
Having understood the basics of Type 2 Slowly Changing Dimensions, now let us look at quality assurance techniques for type 2 Slowly Changing Dimensions.
Scenario 1: Only one record of the current status record for each employee. This can be achieved by running the following query.
|
1 2 3 4 5 6 7 8 |
SELECT [EmployeeNationalIDAlternateKey] ,Count(*) Count FROM [dbo].[DimEmployee] WHERE [Status] = 'Current' GROUP BY [EmployeeNationalIDAlternateKey] HAVING COUNT(*) > 1 |
In the above query, Status is labeled as Current but this can be different in different implementations. EmployeeNationalIDAlternateKey is the business key for the Employee. Depending on the label you need to modify the above query.
Ideally, you should not receive any records for the above query and if there are records, the following query will provide you with the details of those records.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT * FROM DimEmployee WHERE [EmployeeNationalIDAlternateKey] IN ( SELECT [EmployeeNationalIDAlternateKey] FROM [dbo].[DimEmployee] WHERE [Status] = 'Current' GROUP BY [EmployeeNationalIDAlternateKey] HAVING COUNT(*) > 1 ) |
Scenario 2: Should not have the same version for successive records of each business key.
As we discussed at the start, a new record will be added to the dimension table when the status is changed. This scenario is only valid for successive records. This is an important scenario though this is not visible to the end-user. However, if there are unnecessary records in the dimension table, there can be performance issues. Therefore, it is important to identify these records are remove them. However, in every dimension there are internal columns such as surrogate keys, status, start date, end date, etc, that should not be matched. The following script is used to achieve the above scenario.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 |
SELECT EmployeeNationalIDAlternateKey ,SK1 ,SK2 FROM ( SELECT P.EmployeeKey SK1 ,N.EmployeeKey SK2 ,P.EmployeeNationalIDAlternateKey ,CASE WHEN P.ParentEmployeeKey <> N.ParentEmployeeKey THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_ParentEmployeeKey ,CASE WHEN P.EmployeeNationalIDAlternateKey <> N.EmployeeNationalIDAlternateKey THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_EmployeeNationalIDAlternateKey ,CASE WHEN P.ParentEmployeeNationalIDAlternateKey <> N.ParentEmployeeNationalIDAlternateKey THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_ParentEmployeeNationalIDAlternateKey ,CASE WHEN P.SalesTerritoryKey <> N.SalesTerritoryKey THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_SalesTerritoryKey ,CASE WHEN P.FirstName <> N.FirstName THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_FirstName ,CASE WHEN P.LastName <> N.LastName THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_LastName ,CASE WHEN P.MiddleName <> N.MiddleName THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_MiddleName ,CASE WHEN P.NameStyle <> N.NameStyle THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_NameStyle ,CASE WHEN P.Title <> N.Title THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_Title ,CASE WHEN P.HireDate <> N.HireDate THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_HireDate ,CASE WHEN P.BirthDate <> N.BirthDate THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_BirthDate ,CASE WHEN P.LoginID <> N.LoginID THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_LoginID ,CASE WHEN P.EmailAddress <> N.EmailAddress THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_EmailAddress ,CASE WHEN P.Phone <> N.Phone THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_Phone ,CASE WHEN P.MaritalStatus <> N.MaritalStatus THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_MaritalStatus ,CASE WHEN P.EmergencyContactName <> N.EmergencyContactName THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_EmergencyContactName ,CASE WHEN P.EmergencyContactPhone <> N.EmergencyContactPhone THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_EmergencyContactPhone ,CASE WHEN P.SalariedFlag <> N.SalariedFlag THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_SalariedFlag ,CASE WHEN P.Gender <> N.Gender THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_Gender ,CASE WHEN P.PayFrequency <> N.PayFrequency THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_PayFrequency ,CASE WHEN P.BaseRate <> N.BaseRate THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_BaseRate ,CASE WHEN P.VacationHours <> N.VacationHours THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_VacationHours ,CASE WHEN P.SickLeaveHours <> N.SickLeaveHours THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_SickLeaveHours ,CASE WHEN P.SalesPersonFlag <> N.SalesPersonFlag THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_SalesPersonFlag ,CASE WHEN P.DepartmentName <> N.DepartmentName THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_DepartmentName ,CASE WHEN P.STATUS <> N.STATUS THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_Status FROM ( SELECT * ,RANK() OVER ( PARTITION BY EmployeeNationalIDAlternateKey ORDER BY EmployeeKey ) Rank FROM dbo.DimEmployee ) P INNER JOIN ( SELECT * ,RANK() OVER ( PARTITION BY EmployeeNationalIDAlternateKey ORDER BY EmployeeKey ) Rank FROM dbo.DimEmployee ) N ON P.EmployeeNationalIDAlternateKey = N.EmployeeNationalIDAlternateKey AND P.Rank + 1 = N.Rank ) Q WHERE Matched_ParentEmployeeKey = 'MATCHED' AND Matched_EmployeeNationalIDAlternateKey = 'MATCHED' AND Matched_ParentEmployeeNationalIDAlternateKey = 'MATCHED' AND Matched_SalesTerritoryKey = 'MATCHED' AND Matched_FirstName = 'MATCHED' AND Matched_LastName = 'MATCHED' AND Matched_MiddleName = 'MATCHED' AND Matched_NameStyle = 'MATCHED' AND Matched_Title = 'MATCHED' AND Matched_HireDate = 'MATCHED' AND Matched_BirthDate = 'MATCHED' AND Matched_LoginID = 'MATCHED' AND Matched_EmailAddress = 'MATCHED' AND Matched_Phone = 'MATCHED' AND Matched_MaritalStatus = 'MATCHED' AND Matched_EmergencyContactName = 'MATCHED' AND Matched_EmergencyContactPhone = 'MATCHED' AND Matched_SalariedFlag = 'MATCHED' AND Matched_Gender = 'MATCHED' AND Matched_PayFrequency = 'MATCHED' AND Matched_BaseRate = 'MATCHED' AND Matched_VacationHours = 'MATCHED' AND Matched_SickLeaveHours = 'MATCHED' AND Matched_SalesPersonFlag = 'MATCHED' AND Matched_DepartmentName = 'MATCHED' AND Matched_Status = 'MATCHED' |
In the above script, the ranking function is used to match successive records. Each column is matched and if there are any matching records they will be listed out as below.
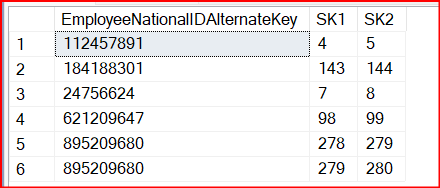
The above figure shows that there are six records with duplicate versions which should be corrected. However, this script is not feasible for practical dimensions as some dimensions will have more than 100 columns. It is not easy to type all those 100 columns. Therefore, the following script is written to find duplicate successive dimension records in a dimension bypassing a few parameters.
In the following script, you need to pass the Dimension Name, its schema name, business key, surrogate key, and the internal columns.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
DECLARE @TableName VARCHAR(255) = 'DimEmployee' DECLARE @SchemaName VARCHAR(255) = 'dbo' DECLARE @BusinessKey VARCHAR(255) = 'EmployeeNationalIDAlternateKey' DECLARE @SurrogateKey VARCHAR(255) = 'EmployeeKey' DECLARE @ExcludedColumns VARCHAR(1000) = @SurrogateKey + ',StartDate,EndDate,CurrentFlag,EmployeePhoto' SELECT 'SELECT ' + @BusinessKey + ',SK1,SK2 FROM ( SELECT P.' + @SurrogateKey + ' SK1,N.' + @SurrogateKey + ' SK2,P.' + @BusinessKey + ',' UNION ALL SELECT 'CASE WHEN P.' + c.NAME + '<>N.' + c.NAME + ' THEN ''NON MATCHED'' ELSE ''MATCHED'' END Matched_' + c.NAME + ',' FROM sys.columns C INNER JOIN sys.tables T ON C.object_id = T.object_id INNER JOIN sys.schemas S ON T.schema_id = S.schema_id WHERE T.NAME = @TableName AND S.NAME = @SchemaName AND C.NAME NOT IN ( SELECT value FROM STRING_SPLIT(@ExcludedColumns, ',') ) UNION ALL SELECT '1 AS T FROM (SELECT *, RANK() OVER(PARTITION BY ' + @BusinessKey + ' ORDER BY ' + @SurrogateKey + ' ) Rank FROM ' + @SchemaName + '.' + @TableName + ') P INNER JOIN ( SELECT * , RANK() OVER(PARTITION BY ' + @BusinessKey + ' ORDER BY ' + @SurrogateKey + ' ) Rank FROM ' + @SchemaName + '.' + @TableName + ') N ON P.' + @BusinessKey + ' = N.' + @BusinessKey + ' AND P.Rank + 1 = N.Rank ) Q' UNION ALL SELECT ' WHERE ' UNION ALL SELECT ' Matched_' + c.NAME + '= ''MATCHED'' AND ' FROM sys.columns C INNER JOIN sys.tables T ON C.object_id = T.object_id INNER JOIN sys.schemas S ON T.schema_id = S.schema_id WHERE T.NAME = @TableName AND S.NAME = @SchemaName AND C.NAME NOT IN ( SELECT value FROM STRING_SPLIT(@ExcludedColumns, ',') ) UNION ALL SELECT ' 1 = 1' |
The above script will generate a script for the validation.
Scenario 3: Finding mismatched records that should not be modified
In some dimensions, some attributes should not be changed. For example, in the Employee dimension Names, date of birth, and joined dates should not be changed. Ideally, if there are changes, they should be overwritten. The following script can be used to achieve the above objectives.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
SELECT EmployeeNationalIDAlternateKey ,SK1 ,SK2 FROM ( SELECT P.EmployeeKey SK1 ,N.EmployeeKey SK2 ,P.EmployeeNationalIDAlternateKey ,CASE WHEN P.FirstName <> N.FirstName THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_FirstName ,CASE WHEN P.LastName <> N.LastName THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_LastName ,CASE WHEN P.MiddleName <> N.MiddleName THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_MiddleName ,CASE WHEN P.NameStyle <> N.NameStyle THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_NameStyle ,CASE WHEN P.Title <> N.Title THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_Title ,CASE WHEN P.HireDate <> N.HireDate THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_HireDate ,CASE WHEN P.BirthDate <> N.BirthDate THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_BirthDate ,CASE WHEN P.LoginID <> N.LoginID THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_LoginID ,CASE WHEN P.EmailAddress <> N.EmailAddress THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_EmailAddress ,CASE WHEN P.STATUS <> N.STATUS THEN 'NON MATCHED' ELSE 'MATCHED' END Matched_Status FROM ( SELECT * ,RANK() OVER ( PARTITION BY EmployeeNationalIDAlternateKey ORDER BY EmployeeKey ) Rank FROM dbo.DimEmployee ) P INNER JOIN ( SELECT * ,RANK() OVER ( PARTITION BY EmployeeNationalIDAlternateKey ORDER BY EmployeeKey ) Rank FROM dbo.DimEmployee ) N ON P.EmployeeNationalIDAlternateKey = N.EmployeeNationalIDAlternateKey AND P.Rank + 1 = N.Rank ) Q WHERE Matched_FirstName = 'NON MATCHED' AND Matched_LastName = 'NON MATCHED' AND Matched_MiddleName = 'NON MATCHED' AND Matched_NameStyle = 'NON MATCHED' AND Matched_Title = 'NON MATCHED' AND Matched_HireDate = 'NON MATCHED' AND Matched_BirthDate = 'NON MATCHED' AND Matched_LoginID = 'NON MATCHED' AND Matched_EmailAddress = 'NON MATCHED' |
Conclusion
In this article, we looked at how to perform testing on Type 2 Slowly Changing Dimensions to improve the performance of the data warehouse queries and other operations. This article looked at three scenarios and scripts were identified.
See more
ApexSQL Complete is a SQL code complete tool that includes features like code snippets, SQL auto-replacements, tab navigation, saved queries and more for SSMS and Visual Studio


View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021