
Q1: What is the difference between a Heap table and a Clustered table? How can we identify if the table is a heap table?
A Heap table is a table in which, the data rows are not stored in any particular order within each data page. In addition, there is no particular order to control the data page sequence, that is not linked in a linked list. This is due to the fact that the heap table contains no clustered index.
A clustered table is a table that has a predefined clustered index on one column or multiple columns of the table that defines the storing order of the rows within the data pages and the order of the pages within the table, based on the clustered index key.
The heap table can be identified by querying the sys.partitions system object that has one row per each partition with index_id value equal to 0. You can also query the sys.indexes system object also to show the heap table index details, that shows, the id of that index is 0 and the type of it is HEAP.
For more information, see the article: SQL Server table structure overview.
Q2: Explain how the SQL Server Engine uses an Index Allocation Map (IAM)?
SQL Server Engine uses an Index Allocation Map (IAM) to keep an entry for each page to track the allocation of these available pages. The IAM is considered as the only logical connection between the data pages, that the SQL Server Engine will use to move through the heap.
For more information, see the article: SQL Server table structure overview.
Q3: What is the “Forwarding Pointers issue” and how can we fix it?
When a data modification operation is performed on heap table data pages, Forwarding Pointers will be inserted into the heap to point to the new location of the moved data. These forwarding pointers will cause performance issues over time due to visiting the old/original location vs the new location specified by the forwarding pointers to get a specific value.
Starting from SQL Server version 2008, a new method was introduced to overcome the forwarding pointers performance issue, by using the ALTER TABLE REBUILD command, that will rebuild the heap table.
For more information, see the article: SQL Server table structure overview.
Q4: What is a SQL Server Index?
A SQL Server index is considered as one of the most important factors in the performance tuning process. Indexes are created to speed up the data retrieval and the query processing operations from a database table or view, by providing swift access to the database table rows, without the need to scan all the table’s data, in order to retrieve the requested data.
You can imagine a table index akin to a book’s index that allows you to find the requested information very fast within your book, rather than reading all the book pages in order to find a specific item you are looking for.
For more information, see the article: SQL Server index structure and concepts.
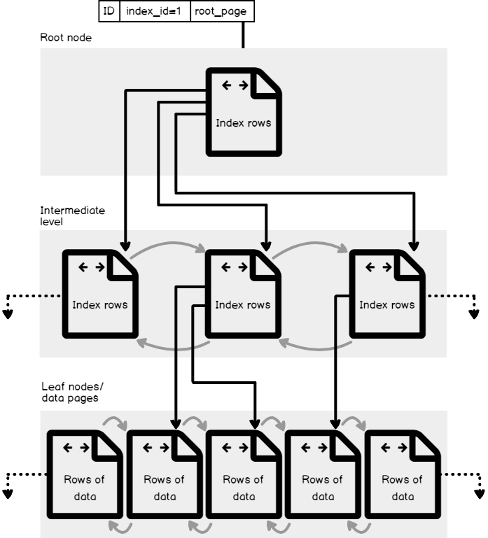
Q5: Describe the structure of a SQL Server Index that provides faster access to the table’s data?
A SQL Server index is created using the shape of B-Tree structure, that is made up of 8K pages, with each page, in that structure, called an index node. The B-Tree structure provides the SQL Server Engine with a fast way to move through the table rows based on index key, that decides to navigate left or right, to retrieve the requested values directly, without scanning all the underlying table rows. You can imagine the potential performance degradation that may occur due to scanning large database table.
The B-Tree structure of the index consists of three main levels:
- the Root Level, the top node that contains a single index page, form which SQL Server starts its data search,
- the Leaf Level, the bottom level of nodes that contains the data pages we are looking for, with the number of leaf pages depends on the amount of data stored in the index,
- and finally the Intermediate Level, one or multiple levels between the root and the leaf levels that holds the index key values and pointers to the next intermediate level pages or the leaf data pages. The number of intermediate levels depends on the amount of data stored in the index.
For more information, see the article: SQL Server index structure and concepts.
Q6: Explain Index Depth, Density and Selectivity factors and how these factors affect index performance?
- Index depth is the number of levels from the index root node to the leaf nodes. An index that is quite deep will suffer from performance degradation problem. In contrast, an index with a large number of nodes in each level can produce a very flat index structure. An index with only 3 to 4 levels is very common.
- Index density is a measure of the lack of uniqueness of the data in a table. A dense column is one that has a high number of duplicates.
- Index selectivity is a measure of how many rows scanned compared to the total number of rows. An index with high selectivity means a small number of rows scanned when related to the total number of rows.
For more information, see the article: SQL Server index structure and concepts.
Q7: What is the difference between OLTP and OLAP workloads and how do they affect index creation decisions?
On Online Transaction Processing (OLTP) databases, workloads are used for transactional systems, in which most of the submitted queries are data modification queries.
In contrast, Online Analytical Processing (OLAP) database workloads are used for data warehousing systems, in which most of the submitted queries are data retrieval queries that filter, group, aggregate and join large data sets quickly.
Creating a large number of indexes on a database table affects data modification (e.g. Updates) operation performance. When you add or modify a row in the underlying table, the row will also be adjusted appropriately in all related table indexes. Because of that, you need to avoid creating a large number of indexes on the heavily modified tables and create the minimum possible number of indexes, with the least possible number of columns on each index. For Online Analytical Processing (OLAP) workloads, in which tables have low modification requirements, you can create a large number of indexes that improve the performance of the data retrieval operations
For more information, see the article: SQL Server index design basics and guidelines.
Q8: Why it is not recommended to create indexes on small tables?
It takes the SQL Server Engine less time scanning the underlying table than traversing the index when searching for specific data. In this case, the index will not be used but it will still negatively affect the performance of data modification operations, as it will be always adjusted when modifying the underlying table’s data.
For more information, see the article: SQL Server index design basics and guidelines.
Q9: What are some different ways to create an index?
- CREATE INDEX T-SQL statement.
- Using SQL Server Management Studio, by browsing the table on which you need to create an index, right click on the Indexes node and choose New Index option.
- Indirectly by defining the PRIMARY KEY and the UNIQUE constraint within the CREATE TABLE or ALTER TABLE statements.
For more information, see the article: SQL Server index operations.
Q10: What are the pros and cons of using ONLINE index creation or rebuilding options?
Setting the ONLINE option to ON when you create or rebuild the index will enable other data retrieving or modification processes on the underlying table to continue, preventing the index creation process from locking the table. On the other hand, the ONLINE index creation or rebuilding process will take longer time than the offline default index creation process.
For more information, see the article: SQL Server index operations.
Q11: What is the difference between PAD_INDEX and FILLFACTOR?
- FILLFACTOR isused to set the percentage of free space that the SQL Server Engine will leave in the leaf level of each index page during index creation. The FillFactor should be an integer value from 0 to 100, with 0 or 100 is the default value, in which the pages will be filled completely during the index creation.
- PAD_INDEX is used to apply the free space percentage specified by FillFactor to the index intermediate level pages during index creation.
For more information, see the article: SQL Server index operations.
Q12: How many Clustered indexes can be created on a table and why?
SQL Server allows us to create only one Clustered index per each table, as the data can be sorted in the table using only one order criteria.
For more information, see the article: Designing effective SQL Server clustered indexes.
Q13: Describe the characteristics ideal Clustered index keys.
- Short: Although SQL Server allows us to add up to 16 columns to the clustered index key, with a maximum key size of 900 bytes, the typical clustered index key is much smaller than what is allowed, with as few columns as possible. A wide Clustered index key will also affect all non-clustered indexes built over that clustered index, as the clustered index key will be used as a lookup key for all the non-clustered indexes pointing to it.
- Static: It is recommended to choose columns that are not changed frequently in a clustered index key. Changing the clustered index key values means that the whole row will be moved to the new proper page to keep the data values in the correct order.
- Increasing: Using an increasing (aka incrementing) column, such as the IDENTITY column, as a clustered index key will help in improving the INSERT process, that will directly insert the new values at the logical end of the table. This highly recommended choice will help in reducing the amount of memory required for the page buffers, minimize the need to split the page into two pages to fit the newly inserted values and the fragmentation occurrence, that required rebuilding or reorganizing the index again.
- Unique: It is recommended to declare the clustered index key column or combination of columns as unique to improve query performance. Otherwise, SQL Server will automatically add a uniqueifier column to enforce the clustered index key uniqueness.
- Accessed frequently: This is due to the fact that the rows will be stored in the clustered index in a sorted order based on that index key that is used to access the data.
- Used in the ORDER BY clause: In this case, there no need for the SQL Server Engine to sort the data in order to display it, as the rows are already sorted based on the index key used in the ORDER BY clause.
For more information, see the article: Designing effective SQL Server clustered indexes.
Q14: Why it is not recommended to use GUID and CHARACTER columns as Clustered index keys?
For GUID columns, that are stored in UNIQUE IDENTIFIER columns, the main challenge that affects the clustered index key sorting performance is the nature of the GUID value that is larger than the integer data types, with 16 bytes size, and that it is generated in random manner, different from the IDENTITY integer values that are increasing continuously.
For the CHARACTER columns. The main challenges include limited sorting performance of the character data types, the large size, non-increasing values, non-static values that often tend to change in the business applications and not compared as binary values during the sorting process, as the characters comparison mechanism depends on the used collation.
For more information, see the article: Designing effective SQL Server clustered indexes.
Q15: What is the main difference between a Clustered and Non-Clustered index structure?
A Non-clustered index is different from a Clustered index in that, the underlying table rows will not be stored and sorted based on the Non-clustered key, and the leaf level nodes of the Non-clustered index are made of index pages instead of data pages. The index pages of the Non-clustered index contain Non-clustered index key values with pointers to the storage location of these rows in the underlying heap table or the Clustered index.
For more information, see the article: Designing effective SQL Server non-clustered indexes.
Q16: What is the main difference between a Non-clustered index that is built over a Heap table and a Non-clustered index that is built over a Clustered table? What is the difference between a RID Lookup and a Key Lookup?
If a Non-Clustered index is built over a Heap table or view (read more about SQL Server indexed views, that have no Clustered indexes) the leaf level nodes of that index hold the index key values and Row ID (RID) pointers to the location of the rows in the heap table. The RID consists of the file identifier, the data page number, and the number of rows on that data page.
On the other hand, if a Non-clustered index is created over a Clustered table, the leaf level nodes of that index contain Non-clustered index key values and clustering keys for the base table, that are the locations of the rows in the Clustered index data pages.
A RID Lookup operation is performed to retrieve the rest of columns that are not available in the index from the heap table based on the ID of each row.
A Key Lookup operation is performed to retrieve the rest of columns that are not available in the index from the Clustered index, based on the Clustered key of each row,
For more information, see the article: Designing effective SQL Server non-clustered indexes.
Q17: How could we benefit from the INCLUDE feature to overcome Non-Clustered index limitations?
Rather than creating a Non-clustered index with a wide key, large columns that are used to cover the query can be included to the Non-clustered index as non-key columns, up to 1023 non-key columns, using the INCLUDE clause of the CREATE INDEX T-SQL statement, that was introduced in SQL Server 2005, with a minimum of one key column.
The INCLUDE feature extends the functionality of Non-clustered indexes, by allowing us to cover more queries by adding the columns as non-key columns to be stored and sorted only in the leaf level of the index, without considering that columns values in the root and intermediate levels of the Non-clustered index. In this case, the SQL Server Query Optimizer will locate all required columns from that index, without the need for any extra lookups. Using the included columns can help to avoid exceeding the Non-clustered size limit of 900 bytes and 16 columns in the index key, as the SQL Server Database Engine will not consider the columns in the Non-clustered index non-key when calculating the size and number of columns of the index key. In addition, SQL Server allows us to include the columns with data types that are not allowed in the index key, such as VARCHAR(MAX), NVARCHAR(MAX), text, ntext and image, as Non-clustered index non-key columns.
For more information, review SQL Server non-clustered indexes with included columns.
Q18: Which type of indexes are used to maintain the data integrity of the columns on which it is created?
Unique Indexes, by ensuring that there are no duplicate values in the index key, and the table rows, on which that index is created.
For more information, see the article: Working with different SQL Server indexes types.
Q19: How could we benefits from a Filtered index in improving the performance of queries?
It uses a filter predicate to improve the performance of queries that retrieve a well-defined subset of rows from the table, by indexing the only portion of the table rows. The smaller size of the Filtered index, that consumes a small amount of the disk space compared with the full-table index size, and the more accurate filtered statistics, that cover the filtered index rows with only minimal maintenance cost, help in improving the performance of the queries by generating a more optimal execution plan.
For more information, see the article: Working with different SQL Server indexes types.
Q20: What are the different ways that can be used to retrieve the properties of the columns participating in a SQL Server index?
- Using SSMS, by expanding the Indexes node under a database tabl, then right-clicking on each index, and choose the Properties option. The problem with gathering the indexes information using the UI method is that you need to browse it one index at a time per each table. You can imagine the effort required to see the article: all indexes in a specific database.
- The sp_helpindex system stored procedure, by providing the name of the table that you need to list its indexes. In order to gather information about all indexes in a specific database, you need to execute the sp_helpindex number of time equal to the number of tables in your database.
- The sys.indexes system dynamic management view. The sys.indexes contains one row per each index in the table or view. It is recommended to join sys.indexes DMV with other systems DMVs, such as the sys.index_columns, sys.columns and sys.tables in order to return meaningful information about these indexes.
For more information, see the article: Gathering SQL Server indexes statistics and usage information.
Q21: How can we get the fragmentation percentage of a database index?
- Using SSMS, from the Fragmentation tab of the index Properties window. Checking the fragmentation percentage of all indexes in a specific database, using the UI method requires a big effort, as you need to check one index at a time.
- The sys.dm_db_index_physical_stats dynamic management function, that was first Introduced in SQL Server 2005. The sys.dm_db_index_physical_stats DMF can be joined with the sys.indexes DMV to return the fragmentation percentage of all indexes under the specified database.
For more information, see the article: Gathering SQL Server indexes statistics and usage information.
Q22: When checking the index usage statistics information, retrieved by querying the sys.dm_db_index_usage_stats dynamic management view, explain the results of the returned number of seeks, scans, lookups and updates.
- The number of Seeks indicates the number of times the index is used to find a specific row,
- the number of Scans shows the number of times the leaf pages of the index are scanned,
- the number of Lookups indicates the number of times a Clustered index is used by the Non-clustered index to fetch the full row
- and the number of Updates shows the number of times the index data has modified.
For more information, see the article: Gathering SQL Server indexes statistics and usage information.
Q23: What is the difference between index Rebuild and Index Reorganize operations?
Index fragmentation can be resolved by rebuilding and reorganizing SQL Server indexes regularly. The Index Rebuild operation removes fragmentation by dropping the index and creating it again, defragmenting all index levels, compacting the index pages using the Fill Factor values specified in rebuild command, or using the existing value if not specified and updating the index statistics using FULLSCAN of all the data.
The Index Reorganize operation physically reorders leaf level pages of the index to match the logical order of the leaf nodes. The index reorganizes operation will be always performed online. Microsoft recommends fixing index fragmentation issues by rebuilding the index if the fragmentation percentage of the index exceeds 30%, where it recommends fixing the index fragmentation issue by reorganizing the index if the index fragmentation percentage exceeds 5% and less than 30%.
For more information, see the article: Maintaining SQL Server indexes.
Q24: How can you find the missing indexes that are needed to potentially improve the performance of your queries?
- The Missing Index Details option in the query execution plan, if available.
- The sys.dm_db_missing_index_details dynamic management view, that returns detailed information about missing indexes, excluding spatial indexes,
- A combination of the SQL Server Profiler and the Database Engine Tuning Advisor tools.
For more information, see the article: Tracing and tuning queries using SQL Server indexes.
Q25: Why is an index described as a double-edged sword?
A well-designed index will enhance the performance of your system and speed up the data retrieval process. On the other hand, a badly-designed index will cause performance degradation on your system and will cost you extra disk space and delay in the data insertion and modification operations. It is better always to test the performance of the system before and after adding the index to the development environment, before adding it to the production environment.

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021