

In the article, we’ll walk through the concepts to understand database snapshots, and their benefits and limitations. This article will help you decide when to use a database snapshot, and when to use a backup. In some cases, the database relying on database backup and restoration operation is not a viable option. Let’s dig into the concepts of database snapshots and see how it differs from a database backup.
Database snapshots are like a view of a database as it was at a certain point in time. It is a read-only copy of the data and the state of the pages, which are made possible using a pointer file called the sparse file. A snapshot contains the original version of pages, and changes in the source since the snapshot was created. However, remember that this is not a full copy of the database.
Snapshots are typically useful for purposes like audits and reporting. Another use for snapshot backups is that multiple snapshots can be created for a database, and these can be taken at different points in time. This helps with period-over-period analyses.
It is important to understand that database snapshots are directly dependent on the source database. Therefore, snapshots can never substitute your regular backup and restore strategy. For instance, if an entire database is lost, it would mean its source files are inconsistent. If the source files are unavailable, snapshots cannot refer to them, and so, snapshot restoration would be impossible.
Snapshots can be created using the CREATE DATABASE command along with the AS SNAPSHOT option. A snapshot always starts with a near-zero size. This is because a snapshot stores changes to the database since the snapshot was created. As changes in the database occur, the snapshot starts to grow, and may even see significant variation in size. Therefore, it is always recommended to keep an eye on them to avoid low-disk-space alerts.
The database snapshot feature is made available in all editions starting with SQL Server 2016 SP1.
| Feature | Enterprise | Standard | Web | Express with Advanced Services | Express |
| Database snapshot | Yes | Yes | Yes | Yes | Yes |
Points to note
- SQL Server Management Studio does not provide a graphical interface for creating snapshots; the only way to create them is using TSQL commands.
- The snapshot file name accepts arbitrary file extensions.
- SQL Server does not support backup operations over sparse files. In other words, sparse files cannot be backed up.
- A database snapshot appears to never change, because read operations on a database snapshot always accesses the original data pages, regardless of where it resides.
- After a page has been updated, a read operation on the snapshot still accesses the original page from the source database, and only the modified pages from the sparse file, also known as the side file.
- DBCC commands use an internal reference of database snapshots to validate the required transactional consistency of the database.
- When we start DBCC CHECKDB, a hidden database snapshot is created. There is no control, however, over these files, since these are created as alternate streams of the files.
- Alternate streams are not used since SQL Server 2014. And the database snapshot is created at the same location as the existing database.
- The database snapshots doesn’t reserve any space; the growth of the snapshot is directly proportional to the transaction rates that occur on the source database.
- The mechanism of reverting the database snapshot doesn’t work on an offline or a corrupted database. Also, reverting doesn’t work if any of the source files that were online when the database snapshot is created, are offline during reversion.
- A database snapshot primarily depends on the side file for each of the data files in the source database. These side files are known as sparse files. Space allocations for these sparse files are made only for the modified portion of the data in the corresponding database file. It doesn’t include an allocation for the remaining portions of the source database—only the changes.
- The side page table stores indicator bits which represents data validity and include an in-memory bit map.
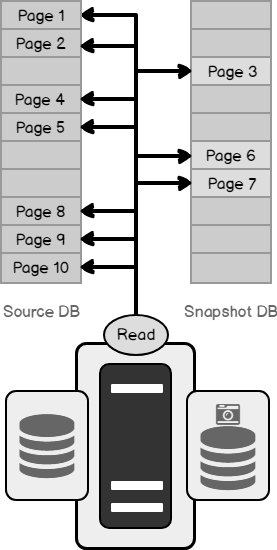
- During a read operation, a database snapshot always accesses the original data pages, regardless of where it resides. In the example below, the data read operation is performed on pages 1 through 10. However, if pages 3, 6 and 7 are the only ones that have changes, the pages 1, 2, 4, 5, 8, 9, 10 are read from the source database, and pages 3, 6, 7 are read from the sparse files.

Lets deep-dive into the concepts using a demo
The following example creates the database SQLShackDSDemo; the first data file is SQLShackDSDemo_dat and the second file is a log file, SQLShackDSDemo_log.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE DATABASE SQLShackDSDemo ON ( NAME = SQLShackDSDemo_dat, FILENAME = 'f:\Program Files\Microsoft SQL Server\MSSQL14.SQL2017\MSSQL\DATA\SQLShackDSDemo_dat.mdf', SIZE = 10, MAXSIZE = 50, FILEGROWTH = 5 ) LOG ON ( NAME = SQLShackDSDemo_log, FILENAME = 'f:\Program Files\Microsoft SQL Server\MSSQL14.SQL2017\MSSQL\DATA\SQLShackDSDemo_log.ldf', SIZE = 5MB, MAXSIZE = 25MB, FILEGROWTH = 5MB ) ; GO |
The next step is to create a table SQLShackAuthorDS and insert dummy records into it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
USE SQLShackDSDemo; GO -- create a table SQLShackAuthorDS CREATE TABLE SQLShackAuthorDS ( ID INT IDENTITY(1,1) PRIMARY KEY NOT NULL, authorName varchar(8000) ); GO -- create a stored procedure to generate 100 rows CREATE PROCEDURE InsertDataSP AS DECLARE @i int = 1 WHILE @i <=100 BEGIN INSERT SQLShackAuthorDS (authorName) VALUES ('SQL Prashanth') Set @i =@i+1 END GO EXECUTE InsertDataSP; GO SELECT * FROM SQLShackAuthorDS; GO |

Let’s now run he is following T-SQL to query the system table called sys.master_files.
We can see that the data file SQLShackDSDemo_Data for the database SQLShackDemo, and the log file for the database, SQLShackDSDemo_log have been created.
|
1 2 3 4 |
-- To fetch the logical name of a data file SELECT name, physical_name, state_desc FROM sys.master_files WHERE database_id = DB_ID(N'SQLShackDSDemo'); |

In this section, we’re going to create a new snapshot for the database, called SQLShackDSDemo_Snapshot. Next, we’ll specify the logical name of the source data file, SQLShackDSDemo_Data, followed by a snapshot file. In this case, these files are created at F:\PowerSQL, as files called, SQLShackDSDemo_SnapshotData with some arbitrary file extension, snap. Finally, we need the clause AS SNAPSHOT OF, followed by the name of the source database.
|
1 2 3 4 5 6 |
-- To create a database snapshot SQLShackDSDemo_Snapshot, source database SQLShackDSDemo CREATE DATABASE SQLShackDSDemo_Snapshot ON (NAME = SQLShackDSDemo_dat, FILENAME = 'f:\PowerSQL\SQLShackDSDemo_SnapshotData.snap') AS SNAPSHOT OF SQLShackDSDemo; GO |
We can now see the Snapshot, called SQLShackDSDemo_Snapshot, in the Database Snapshots folder in the Explorer.

Let’s now query the database snapshot
|
1 2 3 4 5 |
--Query the Snapshot USE SQLShackDSDemo_Snapshot; GO SELECT * FROM SQLShackAuthorDS; GO |

Next, let’s query the system catalog to get the size of the sparse file. To do this, select the is_sparse column from either sys.database_files in the database snapshot or from sys.master_files. This is a boolean flag-like indicator:
- 1 = File is a sparse file.
- 0 = File is not a sparse file.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT DB_NAME(sd.source_database_id) AS [SourceDatabase], sd.name AS [Snapshot], mf.name AS [Filename], size_on_disk_bytes/1024 AS [size_on_disk (KB)], mf2.size/128 AS [MaximumSize (MB)] FROM sys.master_files mf JOIN sys.databases sd ON mf.database_id = sd.database_id JOIN sys.master_files mf2 ON sd.source_database_id = mf2.database_id AND mf.file_id = mf2.file_id CROSS APPLY sys.dm_io_virtual_file_stats(sd.database_id, mf.file_id) WHERE mf.is_sparse = 1 AND mf2.is_sparse = 0 ORDER BY 1; |

Now, perform updates on the source database.
|
1 2 3 4 5 6 7 8 9 |
-- update records to the source database USE SQLShackDSDemo; GO update SQLShackAuthorDS SET authorName='SQLShack Prashanth' where id<50 GO SELECT * FROM SQLShackAuthorDS; GO |

Perform the revert database operation using the snapshot
Let’s see how to revert the accidental updates performed on the source database from the recently taken snapshot
In this example, we revert the changes made on the table, SQLShackAuthorDS, using the snapshot by merging the authorname column based on the id field.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE SQLShackDSDemo; GO update Source SET Source.authorName=snap.authorname FROM SQLShackAuthorDS source inner join SQLShackDSDemo_Snapshot..SQLShackAuthorDS Snap on source.id=snap.id where source.id<50 GO SELECT * FROM SQLShackAuthorDS; GO |
The following output shows that the data is updated

Revert the entire database using restore operation
A database revert operation requires the RESTORE DATABASE permissions on the source database. To revert the database, use the following Transact-SQL statement:
|
1 2 3 4 5 6 7 8 |
RESTORE DATABASE <database_name> FROM DATABASE_SNAPSHOT =<database_snapshot_name> USE master; GO -- Reverting source database from the snapshot RESTORE DATABASE SQLShackDSDemo from DATABASE_SNAPSHOT = 'SQLShackDSDemo_Snapshot'; GO |
Difference between Database backups vs Database snapshots
| Database Backup | Database Snapshot |
| A SQL Server database backup and restore is a means of safeguarding and protecting data in your SQL Server databases | A database snapshot is a read-only, static, transitionally consistent view of the source database. |
| The destination for a SQL Server database backup can be local, remote, network share, or cloud storage | A database snapshot must reside on the same server |
| Can be created using GUI and T-SQL | Can be created only using T-SQL |
| Performance of the system may be impacted only during the backup process. | Performance is impacted during snapshot creation as well as restoration due to increased I/O on the source database resulting from a copy-on-write operation to the snapshot every time a page is updated. |
| Backups can be created at any time. Backups are of various kinds: full, differential, transactional log, etc. Backups are a copy of the entire source (and not just the changes). Restoration can be done to the original location or to a different database or instance. | A snapshot is a “point-in-time” copy of a database. For instance, if you made a snapshot of a database at 1 PM today, and made changes to it, and then decided to bring back the database to how it was at 1, you could perform a restore from the 1 PM snapshot. You just have to ensure that the database files are usable. |
| SQL Server backup depends on physical storage | Snapshots depend on the database but not on the underlying subsystems. This is the reason database snapshot cannot be used as a substitute for the backup-and-restore operation. |
| It’s possible to restore a database with an entirely different name and to a different location. | It’s possible to restore the snapshot only to the same source. |
| Backup and Restore operations on system database is allowed in various scenarios. | Snapshots of the system databases—model, master, and tempdb—are prohibited. |
| The backup and restore operation process works for on any databases. | We cannot backup or restore database snapshots. |
| All the data-pages are to written to the defined storage. | The database snapshot technique uses a special file known as a sparse file. It’s a side file of the source database. It holds the pointers to the original source of the data pages. |
| Backup and restore processed don’t provide for the option to perform object-level restore. |
Snapshots provides an alternate way to rebuild a dropped table or lost data immediately to a different object name and merge the data back into the source database.
The process of reverting is potentially much faster in some cases than restoring from a backup. It’s determined by the size of the database. |
How to decide:
- Snapshot backups can be used for reporting purpose.
- Snapshots provide a historical reference for auditing.
- Reverting the source database to a specific point in time is faster.
- Using database snapshots with database mirroring permits you to make the data on the mirror server accessible for reporting.
- Snapshots safeguard data against accidental changes or human errors.
- Snapshots help with application deployment and release management involving huge data changes or schema modification
- Snapshots help build a test system and quickly run through the testing process.
Summary
In this article, we have discussed the difference between snapshots and backups in SQL Server, making it easier for an administrator to choose between the two available options. We saw that a snapshot represents a point-in-time reference to the original database.
The two are very different techniques and from a performance perspective, a snapshot is created much faster than a backup/restore, but that is because it does not contain any real data when you first create it. Changes to the data pages are written to sparse file only when there is an update on the source database.
You can create more than one snapshot to source database. However, as the number increases, the I/O also increases, which reduces the system performance.
Database snapshots can only be a supplement for backup/restore, never a substitute.
Snapshots are found to be useful for reporting and auditing purposes, since it generally doesn’t involve locking. It is also useful for some application deployment that involves schema-level changes and large bulk updates.
A database snapshot uses the source database files for all read operations. The performance of the queries directly depends on how busy the source database is, the rate at which the transactions occur on the source database, how many queries are run simultaneously on both the databases, disk IO, hardware performance, etc.
Table of contents
References
- Database snapshot in SQL Server
- View the Size of the Sparse File of a Database Snapshot (Transact-SQL)
- Revert a Database to a Database Snapshot
- View a Database Snapshot (SQL Server)
See more
For High-speed SQL Server backup, compression and restore see Quest LiteSpeed, an enterprise tool to schedule, automate and backup SQL databases


My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021