
SQL Server backups, in itself, is a vast subject; so vast, there are multiple books written about them. In this article, however, we are going to focus on the types of backups that are available to us, and understand how to pick what we need, and what aspects we base that decision on. This understanding would, in turn, help us decide our backup-and-restore strategy.
Following are the most common types of backups available in SQL Server:
- Full
- Differential
- Transaction log
- Tail Log backup
There are other backup types available as well:
- Copy-only backup
- File backups
- Partial backups.
Full backups
A full backup, as the name implies, backs up everything. It is the foundation of any kind of backup. This is a complete copy, which stores all the objects of the database: Tables, procedures, functions, views, indexes etc. Having a full backup, you will be able to easily restore a database in exactly the same form as it was at the time of the backup.
A full backup creates a complete backup of the database as well as part of the transaction log, so the database can be recovered. This allows for the simplest form of database restoration, since all of the contents are contained in one single backup.
A full backup must be done at least once before any of the other types of backups can be run—this is the foundation for every other kind of backup.
How to create full database backup using T-SQL
The BACKUP DATABASE is the command used to create a full database backup. It requires at least two input parameters: the database name and the backup device.
Following is the example for a full database backup to be stored in a device:
|
1 2 3 4 5 |
BACKUP DATABASE [SQLShackDemoATC] To DISK='f:\PowerSQL\SQLShackDemoATC.BAK' WITH FORMAT, MEDIANAME = 'Native_SQLServerBackup', NAME = 'Full-SQLShackDemoATC backup'; |
Full Database Backup to Multiple files
Sometimes in some instances, we’re limited by the amount of space we have. What if we wanted to backup an entire database that is huge? Or what if we have to copy the backup files over the network? It might be a good idea in these cases to split the backup into smaller chunks—each being a separate file.
|
1 2 3 4 5 6 |
BACKUP DATABASE SQLShackDemoATC TO DISK = 'f:\PowerSQL\SQLShackDemoATC_1.BAK', DISK = 'f:\PowerSQL\SQLShackDemoATC_2.BAK', DISK = 'f:\PowerSQL\SQLShackDemoATC_3.BAK', DISK = 'f:\PowerSQL\SQLShackDemoATC_4.BAK' WITH INIT, NAME = 'FULL SQLShackDemoATC backup', STATS = 5 |
If you’d like to create a mirror copy of the backup file:
|
1 2 3 4 |
BACKUP DATABASE ProdSQLShackDemo TO DISK = 'F:\PowerSQL\ProdSQLShackDemo_1.BAK' MIRROR TO DISK = 'F:\PowerSQL\ProdSQLShackDemo_2.BAK' WITH FORMAT |
You can, in fact, have up to three mirror copies:
|
1 2 3 4 5 6 7 |
BACKUP DATABASE ProdSQLShackDemo TO DISK = 'F:\PowerSQL\ProdSQLShackDemo_1.BAK' MIRROR TO DISK = 'F:\PowerSQL\ProdSQLShackDemo_2.BAK' MIRROR TO DISK = 'F:\PowerSQL\ProdSQLShackDemo_3.BAK' MIRROR TO DISK = 'F:\PowerSQL\ProdSQLShackDemo_4.BAK' WITH FORMAT GO |
Differential Backups
A differential database backup is the superset of the last full backup and contains all changes that have been made since the last full backup. So, if there are very few transactions that have happened recently, a differential backup might be small in size, but if you have made a large number of transactions, the differential backup could be very large in size.
As a differential backup doesn’t back up everything, the backup usually runs quicker than a full backup. A differential database backup captures the state of the changed extents at the time that backup was created. If you create a series of differential backups, a frequently-updated database is likely to contain different data in each differential. As the differential backups increase in size, restoring a differential backup can significantly increase the time that is required to restore a database. Therefore, it is recommended to take a new full backup, at set intervals, to establish a new differential base for the data.
Differential backups save storage space and the time it takes for a backup. However, as data changes over time, the differential backup size also increases. The longer the age of a differential backup and larger the size and at some point in time it may reach the size of the full backup. A large differential backup loses the advantages of a faster and smaller backup as it requires the full backup to be restored before restoring the recent differential backup. Typically, we would restore the most recent full backup followed by the most recent differential backup that is based on that full backup.
How to create Differential database backup using T-SQL
The BACKUP DATABASE command is used with the differential clause to create the differential database backup. It requires three parameters:
- Database name
- Backup device
- The DIFFERENTIAL clause
For example,
|
1 2 3 4 5 |
BACKUP DATABASE [SQLShackDemoATC] To DISK='f:\PowerSQL\SQLShackDemoATC_Diff.BAK' WITH DIFFERENTIAL, MEDIANAME = 'Native_SQLServerDiffBackup', NAME = 'Diff-SQLShackDemoATC backup'; |
Transaction Log Backup
The log backup, as its name implies, backs up the transaction logs. This backup type is possible only with full or bulk-logged recovery models. A transaction log file stores a series of the logs that provide the history of every modification of data, in a database. A transaction log backup contains all log records that have not been included in the last transaction log backup.
It allows the database to be recovered to a specific point in time. This means that the transaction log backups are incremental and differential backups are cumulative in nature. If you want to restore the database to a specific point in time, you need restore a full, recent differential, and all the corresponding transaction log records which are necessary to build the database up to that specific point, or to a point very close to the desired point in time, just before the occurrence of the accident that resulted in the data loss. This series of modifications is contained and maintained using LSN (Log Sequence Number) in the log chain. A log backup chain is an unbroken series of logs that contain all the transaction log records necessary to recover a database to a point in time. A log chain always starts with a full database backup and continues until for reason it breaks the chain (for example, changing the recovery model of database to simple, or taking an extra full backup), thus by preventing log backups from being taken on the database until another full (or differential) backup is initiated for that database.
How to create Transactional log backup using T-SQL
The BACKUP LOG command is used to backup the transaction log. It requires the database name, the destination device and the TRANSACTION LOG clause to initiate the transaction log backup.
|
1 2 3 4 5 6 |
BACKUP LOG [SQLShackDemoATC] To DISK='f:\PowerSQL\SQLShackDemoATC_Log.trn' WITH MEDIANAME = 'Native_SQLServerLogBackup', NAME = 'Log-SQLShackDemoATC backup'; GO |

Tail log backups
In the event of a failure, when you need the database to get back up and running, and the database is operating in FULL or BULK_LOGGED recovery model, it’s always easy to start the recovery operation and start restoring the backups. But before that, the first action to be taken after the failure is what is called as a tail log backup of the live transaction log.
This is an intermediate step that we need to take before we start the restoration. This process is called tail log backup restoration.
|
1 2 3 4 5 6 7 |
USE master; GO -- create a tail-log backup BACKUP LOG [SQLShackDemoATC] TO DISK = 'f:\PowerSQL\SQLShackDemoATCTailLog.log' WITH CONTINUE_AFTER_ERROR; GO |
The WITH CONTINUE_AFTER_ERROR clause will force SQL Server to store the log file, even though it’s generating an error.
Copy_Only backup
A copy-only backup is a special type of full backup, which is independent of the conventional sequence of backups. The difference between copy-only and a full backup is that a copy-only backup doesn’t become a base for the next differential backup.
A full backup works on all database recovery models. Copy-only backup, on the other hand, is applicable only to a full or bulk-logged recovery models. The restoration of a copy-only backup is no different than a normal restoration process.
Performing the copy-only backup is pretty simple. The syntax would look something like this:
|
1 2 3 4 5 6 7 8 9 |
BACKUP DATABASE [SQLShackDemoATC] To DISK='f:\PowerSQL\SQLShackDemoATC_1.BAK' WITH COPY_ONLY, MEDIANAME = 'Native_SQLServerFullBackup', NAME = 'Full-SQLShackDemoATC backup'; BACKUP LOG [SQLShackDemoATC] TO DISK = 'f:\PowerSQL\SQLShackDemoATCCopyOnly.log' WITH COPY_ONLY; GO |
The BACKUP LOG command with the COPY_ONLY option generates a copy-only log backup. It doesn’t involve in transaction log truncation.

It is necessary to use “COPY_ONLY” backup option in order to preserve the database backup sequence.

Partial backups
Partial backups are one of the least-used backup methods available in SQL Server. All database recovery models support partial backups, but partial backups are mostly used in the simple recovery model in order to improve flexibility when backing up large databases that contain read-only filegroups.
The READ_WRITE_FILEGROUPS option is used with the BACKUP DATABASE command. This command is for partial backup. It processes the backup of read-write file groups.
SQLShackPartialBackup is the database created with primary and secondary file groups. Let’s use this database for this demo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE DATABASE SQLShackPartialBackup ON PRIMARY ( NAME = N'SQLShackPartialBackup_1', FILENAME = N'f:\PowerSQL\SQLShackPartialBackup_1.mdf' , SIZE = 5000KB , FILEGROWTH = 1024KB ), FILEGROUP [Secondary] ( NAME = N'SQLShackPartialBackup_2', FILENAME = N'f:\PowerSQL\SQLShackPartialBackup_2.mdf' , SIZE = 5000KB , FILEGROWTH = 1024KB ) LOG ON ( NAME = N'SQLShackPartialBackup_Log', FILENAME = N'f:\PowerSQL\SQLShackPartialBackup_log.ldf' , SIZE = 1024KB , FILEGROWTH = 10%) GO |
Let’s change the recovery model of the database to SIMPLE using the following ALTER statement
|
1 |
ALTER DATABASE SQLShackPartialBackup SET RECOVERY SIMPLE |
Now, set the secondary file-group to READONLY mode
|
1 |
ALTER DATABASE SQLShackPartialBackup MODIFY FILEGROUP [Secondary] READONLY |
Initiate a backup using the READ_WRITE_FILEGROUPS option
|
1 2 3 |
BACKUP DATABASE SQLShackPartialBackup READ_WRITE_FILEGROUPS TO DISK = N'f:\PowerSQL\SQLShackPartialBackup_Full.bak' GO |
We can see in the following screenshot that the SQLShackPartialBackup_2 filegroup is not been backed up in the backup process.

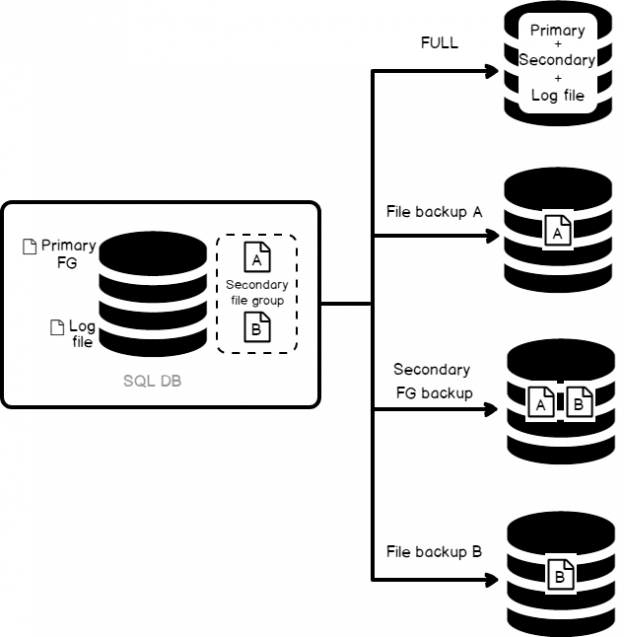
File and File Group Backups
This topic is relevant for SQL Server databases that contain multiple files or filegroups. File backups of read-only filegroups can be combined with partial backups. Partial backups include all the read/write filegroups and, optionally, one or more read-only filegroups.
Let’s create a database with multiple files and filegroups.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE DATABASE SQLShackFileBackup ON PRIMARY ( NAME = N'SQLShackFileBackup_1', FILENAME = N'f:\PowerSQL\SQLShackFileBackup_1.mdf' , SIZE = 5000KB , FILEGROWTH = 1024KB ), FILEGROUP [Secondary] ( NAME = N'SQLShackFileBackup_2', FILENAME = N'f:\PowerSQL\SQLShackFileBackup_2.ndf' , SIZE = 5000KB , FILEGROWTH = 1024KB ) LOG ON ( NAME = N'SQLShackFileBackup_Log', FILENAME = N'f:\PowerSQL\SQLShackFileBackup_Log.ldf' , SIZE = 1024KB , FILEGROWTH = 10%) GO |
The following examples demonstrates how to create the file-level backup of the files:
|
1 2 3 4 5 |
BACKUP DATABASE SQLShackFileBackup FILE = 'SQLShackFileBackup_1', FILE = 'SQLShackFileBackup_2' TO DISK = 'f:\PowerSQL\SQLShackGroupfiles.bak'; GO |
The following example illustrates the full file backup of all the files in both of the primary and secondary file-groups.
|
1 2 3 4 5 |
BACKUP DATABASE SQLShackFileBackup FILEGROUP = 'PRIMARY', FILEGROUP = 'Secondary' TO DISK = 'f:\PowerSQL\SQLShackGroupfilegroup.bak'; GO |

Backup Set Options
The following are the few options that operate on the database backup set that would be created using backup database command
WITH Options
The WITH clause is used with the BACKUP command in case we have additional backup requirements.
COMPRESSION: This option enables backup compression. NO_COMPRESSION explicitly disables the backup compression. Compression is turned off during backups by default.
ENCRYPTION: An encryption algorithm can be specified with BACKUP to secure the backup files stored offsite. You can specify NO_ENCRYPTION when you don’t need backup encryption.
Media set Options
FORMAT: This option used to specify whether to overwrite the media header information. The FORMAT clause will create a new media backup set, whereas NOFORMAT will preserve all the information.
INIT: INIT is used to create a new backup set; NOINIT is used for appending the backup to the existing backup set. The NOINIT parameter is used mostly when you backup the database to a tape device.
NAME: The NAME parameter is used to identify the backup set.
SKIP: The skip parameter is used to skip the expiration check on the backup set.
NOREWIND: This parameter is used to keep a tape device open and ready for use
NOUNLOAD: This parameter is used to instruct SQL Server to not unload the tape from the drive upon completion of the backup operation.
STATS: The STATS option is useful to get the status of the backup operation at regular stages of its progress.
Summary
Planning backups is relatively simpler for smaller databases. As the databases grow in size the management of backup can quickly become a complex and tedious job.
With planning and the defining right backup and restore/recovery strategy, we would place ourselves in a good position against any sort of failure.
A full backup is always easier to restore but it is a resource-intensive operation and takes longer to complete.
We’ve covered different backup types with examples in this article. This gives you an idea of the available backup types and the basic purpose of each backup type.
For example, for an index rebuild operation, consider the time required and make sure it only occurs right before a full backup so that all of those changes don’t need to be rolled up into differential backups.
To speed up a backup operation, consider moving historical data to archive file-groups and split the read-write data and read-only data into separate file-groups. This gives you the flexibility to backup only the read-write file-groups and their respective files.
Using the available backup compression options, we can reduce the amount of data that needs to be backed up. This removes the extra burden on the storage and transfer resources needed for the entire operation.
That’s all for now. Stay tuned for more updates!
Table of contents
References

My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021