
In the first part of this series Getting Started with Azure Cosmos DB, we looked at using Azure Cosmos DB for saving an individual’s fitness routine and why this database structure is better for this data than a SQL database while also showing that we still have to organize our structure like a file system organizes files. In this part of our series, we’ll begin looking at the terminology translation between NoSQL and SQL along with running updates for our documents and queries with filters that return some fields in our document, but not other fields.
Terminology
In SQL Server, we have a data structure that involves the server, database, table, rows and columns of data along with other database objects, such as stored procedures, views, functions, etc. With Azure Cosmos DB (and MongoDB), we have similar terminology, though an individual’s document structure may use a format that could be another document within it itself. For a helpful understanding of translating between SQL and NoSQL in most cases, we use the below with NoSQL databases:
- Collection: similar to a table
- Document: similar to a row of data
- Field: similar to a column
- Document objects: from arrays to subdocuments within a document, these can be similar to documents, table-like structures, etc.
Because documents can store data in many different formats, these terms help us translate what we’re referring to, but are not exact duplicate terms of their SQL counterparts, since NoSQL and SQL fundamentally differ.
Updating Our Documents
We created five documents in our Azure Cosmos DB and we’ll first start by updating these documents with numerical values for measurements so that we can compare them when we add data. We’ll start by querying our first document by using our unique identifier of the date and time of our routine (datetimeRoutine) in the Shell that we’ll want to update.

We return the specific document using our unique identifier involving time.
Next, we’ll run our update statement. We first specify the unique identifier of our document – in this case the date and time of the routine – then in the next set of brackets, we update the existing document fields. We only include the fields that we’re updating (in this example 2 fields). If we were to change the name of our fields, these would become additions to our document, not updates to our document. Additions would be another field – it wouldn’t update an existing field. If we want to add another field to a document, we can do so as we see with the field notes that we add to our first document in this Azure Cosmos DB collection.

Similar to a technique we use in SQL Server, with Azure Cosmos DB, we can update a document by first removing the document and adding the document again (notice how the _id field will change – which is automatically created since this is a MongoDB API). This technique becomes incredibly useful when we have a development situation where we work with full documents in an object-level that may have many fields change and we want to simply remove and add the document. Context around performance matters: in some situations, we want to update the document, while in other situations, removing and adding a new document outperforms an update.
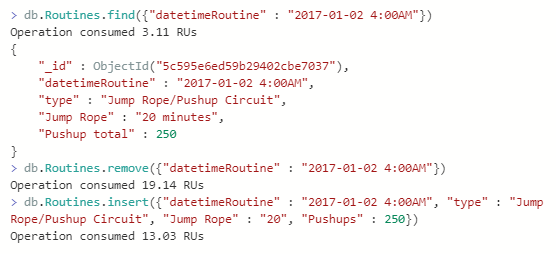
We can remove a document and re-add it, which is a useful development technique when we have many changes rather than performing an update.

We’ve updated the document by removing and re-adding and we see that the _id field differs.
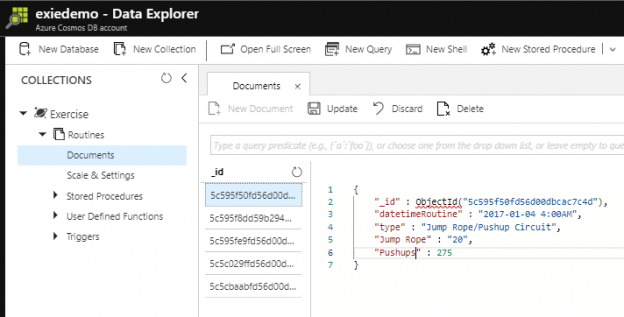
We can also select the document within the collection itself through the interface and update the fields and information directly, which may be useful if we’re using the Azure Cosmos DB as a configuration database or for dynamic meta information related to apps or processes and we have few documents. In the below images, I first select a document that I want to update (datetimeRoutine of 2017-01-04 4:00AM), update the fields, then click update.

First we select the document we want to update

Second, we make our updates in the document then click “Update.”
Our final document to update is datetimeRoutine of 2017-01-07 4:00AM and in this case, we won’t add a notes field because our first Treadmill Run value had notes explaining how this is formatted. We have this flexibility with NoSQL databases like Azure Cosmos DB where a first value of a similar document has an explanation – and this is entirely optional for our database. We may choose to have no explanation in any document, but since documents aren’t required to have the exact same number of fields, we have this choice.

Our final update.
Querying Related Documents
Before we begin querying related documents in our Azure Cosmos DB, we’ll add five more documents which follow similar structure to the documents that we updated – we can add these directly with the “New Document” option or through the Shell (I’ve formatted it for the Shell, but either will add the document):
|
1 2 3 4 5 |
db.Routines.insert({"datetimeRoutine" : "2017-01-09 4:00AM", "type" : "Jump Rope/Pushup Circuit", "Jump Rope" : "20", "Pushups" : 290}) db.Routines.insert({"datetimeRoutine" : "2017-01-12 4:00AM", "type" : "Jump Rope/Pushup Circuit", "Jump Rope" : "21", "Pushups" : 300}) db.Routines.insert({"datetimeRoutine" : "2017-01-10 4:00AM", "type" : "Treadmill Run", "distance" : "3.1", "time" : "30"}) db.Routines.insert({"datetimeRoutine" : "2017-01-13 4:00AM", "type" : "Treadmill Run", "distance" : "3.25", "time" : "30"}) db.Routines.insert({"datetimeRoutine" : "2017-01-11 4:00AM", "type" : "Endurance", "Pushup AMRAP" : 1050}) |
When we’re done adding the five documents, after refreshing the collection, we’ll see the total of ten documents – the _id field will differ in your Azure Cosmos DB, since this field is automatically generated:

We now have 10 documents in our collection (your _id values will differ).
Next, we’ll query our database for our Treadmill Runs and we’ll notice that in our output we get a lot of fields that we may not want – such as the _id field and the type field (since it’s already being filtered for in this query). Just like with selecting columns in SQL Server, we may only want to select some fields from a collection. For using documents from an Azure Cosmos DB, if we use documents to have data values extracted into a SQL report or another BI report, we will more than likely want some fields of a document, not the entire document.

While we get the correct result, we may not want every field in these documents.
We’ll specify which columns that we want returned in our query and since our query already is filtering on an exercise (“Treadmill Run”), we’ll leave out this field. What we want is the date, distance and time of the exercise. For this, we’ll specify the fields in our query that we want with the selection of 1 – meaning that we want the field to return (0 would be the opposite, do not return). For developers familiar with MongoDB, this syntax is identical and is part of what makes Azure Cosmos DB running the MongoDB API easy to use.

We still see the _id field, even though we didn’t specify it.
The documents return and we see that they all have the _id field that’s automatically generated on each document. The reason for this is because the _id field is default and we can remove it by specifying it with the option of 0:

The _id field is now removed with our specifications of 0.
The reason I mentioned we can specify 0 is because we can write this same query in a different way – setting the two fields we don’t want to 0 since there are fewer fields that we don’t want than what we want – and notice that we get the same results and our query was faster to write:

We return the same data by specifying the columns we don’t want.
Imagine that we had 100 fields and we wanted 97 of them – being able to specify returning all fields except 3 in this case would save us a lot of time. Sometimes we work with data sets like this – we have fields for order and querying, but we don’t want those particular fields returning because they are unnecessary, like the field “type” in the above example – we’re already filtering by it, so we don’t need it to return.
Summary
As we see with Azure Cosmos DB, it’s helpful to understand the terminology such as collections, documents and fields and see how they have similar patterns to what we find in SQL with tables, rows and columns. We also saw how to run updates on our documents and like with SQL Server, we always want to verify that a CRUD operation such as update processed correctly. Finally, we looked at querying our data by returning some fields, but not other fields. We will use data sets where we want everything, except for a few fields, and we see that we can conveniently run these types of queries to save development time.
Table of contents
| Getting Started with Azure Cosmos DB |
| Updating and Querying Details in Azure Cosmos DB |
| Applying Field Operators and Objects in Azure Cosmos DB |
| Getting Started with Subdocuments in Azure Cosmos DB |

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020