

Introduction
In the first part of this article, we will discuss about parallelism in the SQL Server Engine. Parallel processing is, simply put, dividing a big task into multiple processors. This model is meant to reduce processing time.
- SQL Server can execute queries in parallel
- SQL Server creates a path for every query. This path is execution plan
- The SQL Server query optimizer creates execution plans
- SQL Server query optimizer decides the most efficient way for create execution plan
Execution plans are the equivalent to highways and traffic signs of T-SQL queries. They tell us how a query is executed.
In the SQL Server Engine, there is a parameter to set up a limit aka governor for CPU usage. This setting name is MAXDOP (maximum degree of parallelism). We can set this parameter in T-SQL or SQL Server Management Studio under the properties of the server. “0” means SQL Server can use all processors if they are necessary
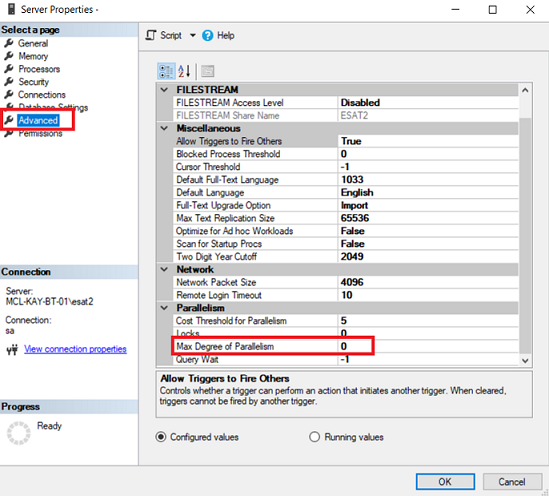
We can change this option using the following T-SQL script
|
1 2 3 4 5 6 7 |
EXEC sp_configure 'max degree of parallelism', 4; GO RECONFIGURE WITH OVERRIDE; GO EXEC sp_configure 'max degree of parallelism' |
Parallel execution plans, MAXDOP and ENABLE_PARALLEL_PLAN_PREFERENCE
The Query optimizer analyzes possible execution plans and then chooses the optimal execution plan. This selection is based on the value of query estimated cost. In some cases, the SQL Server query optimizer chooses a parallel execution plan, primarily because the SQL Server query optimizer decides a parallel execution plan cost is more optimum than a serial execution plan.
Now we will look at some examples of parallel execution plans and properties. This query will generate a parallel execution plan.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
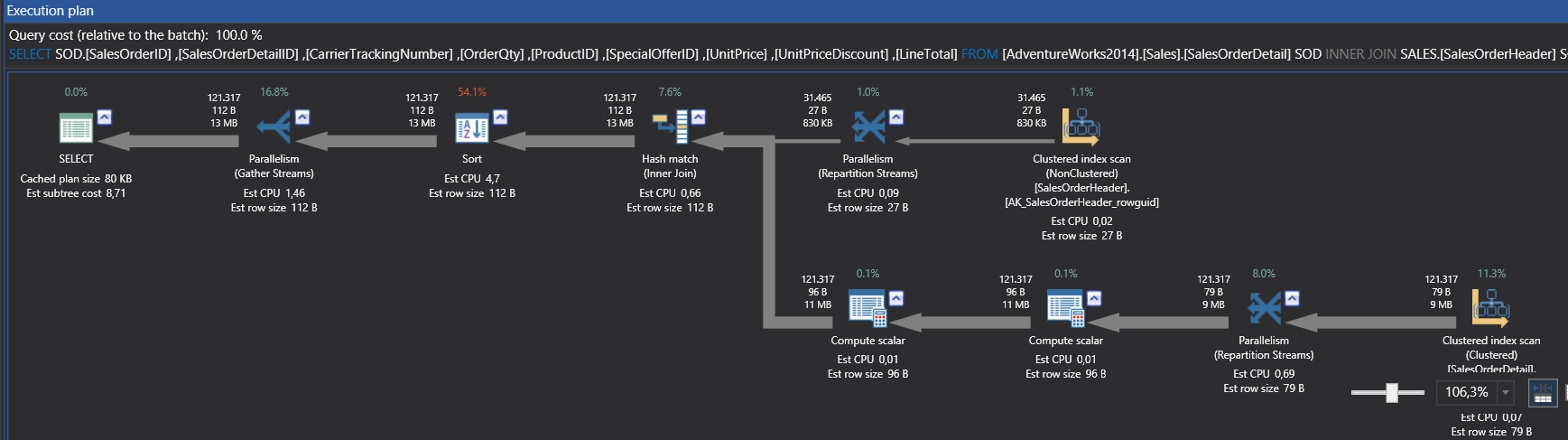
SELECT SOD.[SalesOrderID] ,[SalesOrderDetailID] ,[CarrierTrackingNumber] ,[OrderQty] ,[ProductID] ,[SpecialOfferID] ,[UnitPrice] ,[UnitPriceDiscount] ,[LineTotal] FROM [Sales].[SalesOrderDetail] SOD INNER JOIN SALES.[SalesOrderHeader] SOH ON SOD.SalesOrderID = SOH.SalesOrderID ORDER BY SOD.ModifiedDate DESC , SOH.rowguid DESC |
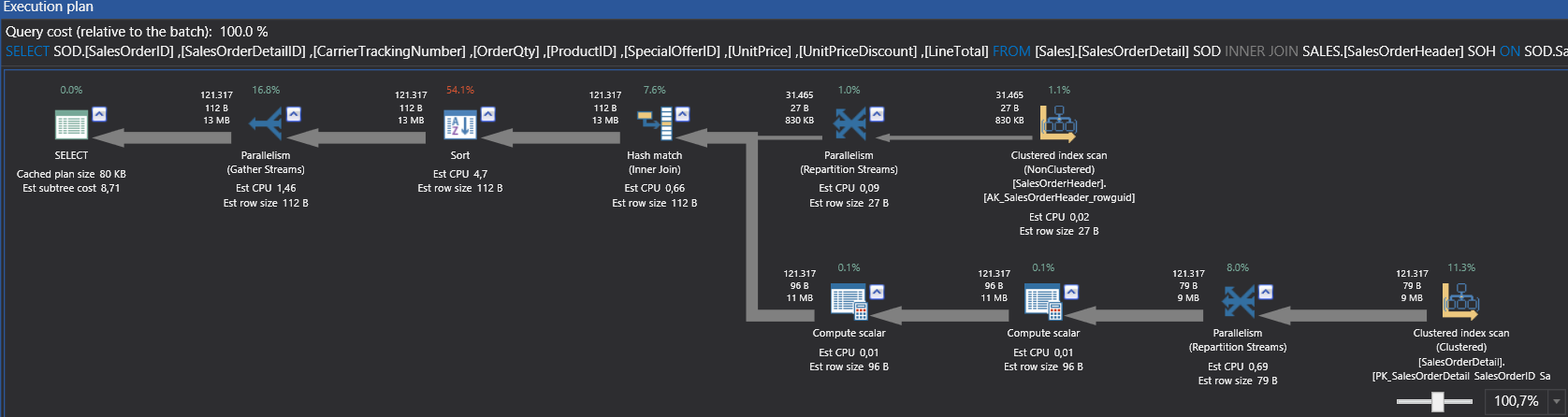

In the previous example, we can see parallel operators and as has been highlighted, Degree of Parallelism show us how many threads are used in this query.
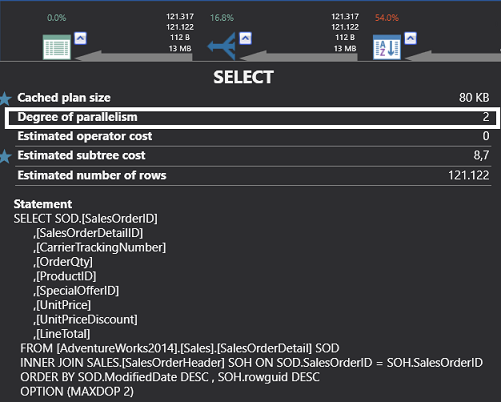
In this step, we will look at the MAXDOP query hint. We can dictate to the SQL Server query optimizer how many threads will run in parallel. This hint specifies the number of threads for the query. We will apply this query hint to the following query and we will change our degree of parallelism to 2
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT SOD.[SalesOrderID] ,[SalesOrderDetailID] ,[CarrierTrackingNumber] ,[OrderQty] ,[ProductID] ,[SpecialOfferID] ,[UnitPrice] ,[UnitPriceDiscount] ,[LineTotal] FROM [AdventureWorks2014].[Sales].[SalesOrderDetail] SOD INNER JOIN SALES.[SalesOrderHeader] SOH ON SOD.SalesOrderID = SOH.SalesOrderID ORDER BY SOD.ModifiedDate DESC , SOH.rowguid DESC OPTION (MAXDOP 2) |
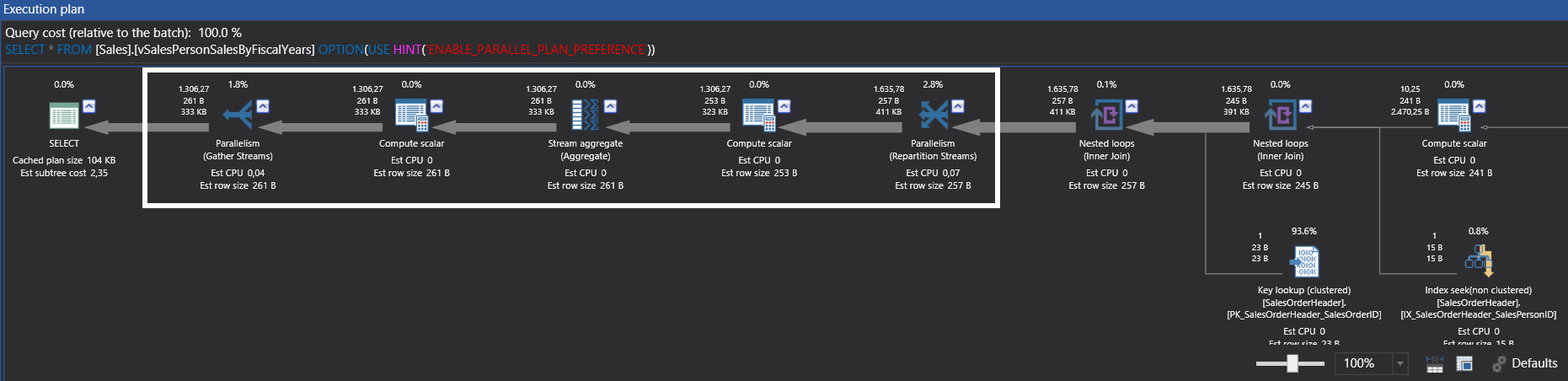
A new query hint is supported in SQL Server 2016 SP1 or above versions. This hint is ENABLE_PARALLEL_PLAN_PREFERENCE. It allows us to force the SQL Server query optimizer to select parallel plan instead of serial plan.
We will use ENABLE_PARALLEL_PLAN_PREFERENCE in this query and the Query Optimizer will generate a parallel plan.
- Parallel execution plan with “ENABLE_PARALLEL_PLAN_PREFERENCE” query hint
|
1 2 3 4 5 |
SELECT * FROM [Sales].[vSalesPersonSalesByFiscalYears] OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')) |
- Parallel execution plan without ENABLE_PARALLEL_PLAN_PREFERENCE query hint
|
1 2 3 4 |
SELECT * FROM [Sales].[vSalesPersonSalesByFiscalYears] |
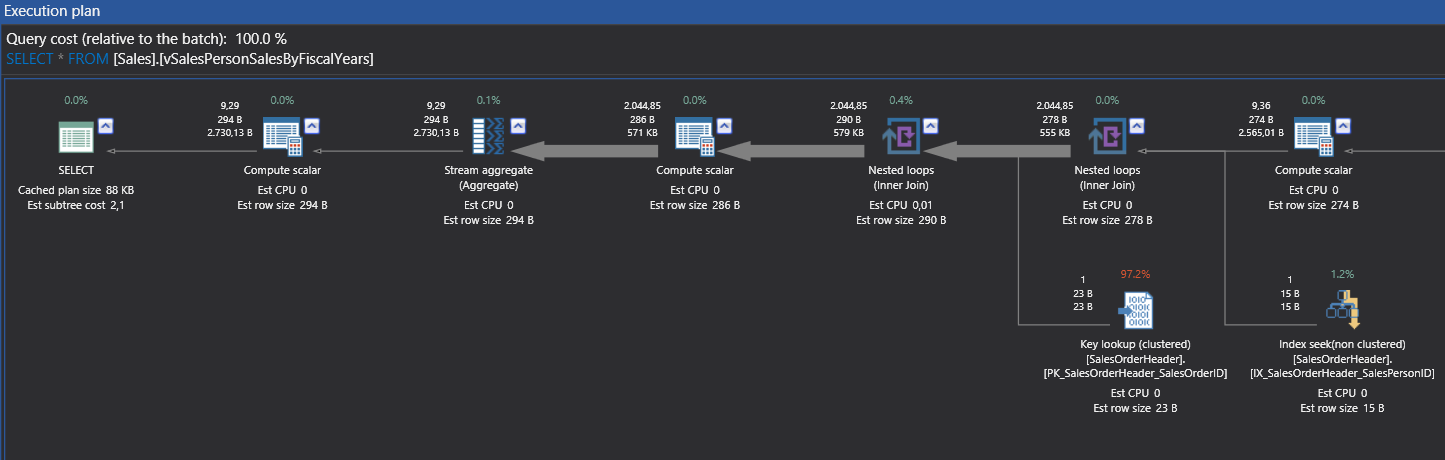
To this point, we have discussed SQL Server query optimizer parallel processing decision, mechanism, and usage. Next, we will discuss SQL Server 2016 parallel insert and performance impact.
Parallel insert
In SQL Server 2016, Microsoft has implemented a parallel insert feature for the INSERT … WITH (TABLOCK) SELECT… command. The parallel insert functionality has proven to be a really useful tool for ETL / data loading workloads which will result in great improvements for data loading. This is important because, in data loading, performance and time is a key metric.
We will look for answers to the following questions in the next section of the article
- How parallel insert work
- How parallel insert improves performance
- How parallel insert generates execution plans
Requirements
- SQL Server 2016 installed
- WideWorldImporters Database (Microsoft new sample database for SQL Server)
Create a sample for parallel insert
We will use [Warehouse].[StockItemTransactions] table. To enlarge the data, we will create dummy source destination and insert records
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
USE WideWorldImporters GO DROP TABLE IF EXISTS [DummySource_Table] CREATE TABLE [DummySource_Table]( [Id_Source] [int] IDENTITY(1,1), [StockItemID_Source] [int] NOT NULL, [TransactionTypeID_Source] [int] NOT NULL, [CustomerID_Source] [int] NULL, [InvoiceID_Source] [int] NULL, [SupplierID_Source] [int] NULL, [PurchaseOrderID_Source] [int] NULL, [TransactionOccurredWhen_Source] [datetime2](7) NOT NULL, [Quantity_Source] [decimal](18, 3) NOT NULL, [LastEditedBy_Source] [int] NOT NULL, [LastEditedWhen_Source] [datetime2](7) NOT NULL) GO INSERT INTO [DummySource_Table] SELECT [StockItemID] ,[TransactionTypeID] ,[CustomerID] ,[InvoiceID] ,[SupplierID] ,[PurchaseOrderID] ,[TransactionOccurredWhen] ,[Quantity] ,[LastEditedBy] ,[LastEditedWhen] FROM [Warehouse].[StockItemTransactions] GO 200 |
This number defines how many times the record will be added.
In this step we will create destination table
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DROP TABLE IF EXISTS [ParallelInsert_Destination] GO CREATE TABLE [dbo].[ParallelInsert_Destination]( [Id_Source] [int] NOT NULL, [StockItemID_Source] [int] NOT NULL, [TransactionTypeID_Source] [int] NOT NULL, [CustomerID_Source] [int] NULL, [InvoiceID_Source] [int] NULL, [SupplierID_Source] [int] NULL, [PurchaseOrderID_Source] [int] NULL, [TransactionOccurredWhen_Source] [datetime2](7) NOT NULL, [Quantity_Source] [decimal](18, 3) NOT NULL, [LastEditedBy_Source] [int] NOT NULL, [LastEditedWhen_Source] [datetime2](7) NOT NULL ) |
We will look at parallel and serial insert query differences.
Parallel execution:
|
1 2 3 4 5 6 |
SET STATISTICS TIME ON TRUNCATE TABLE [ParallelInsert_Destination] INSERT INTO [ParallelInsert_Destination] WITH(TABLOCK) SELECT * FROM [DummySource_Table] |
Tip:
TABLOCK hint provides lock escalation on the table level for source tables. Table level exclusive locks reduce concurrency, which means another sessions cannot insert or update a table when the parallel insert is running
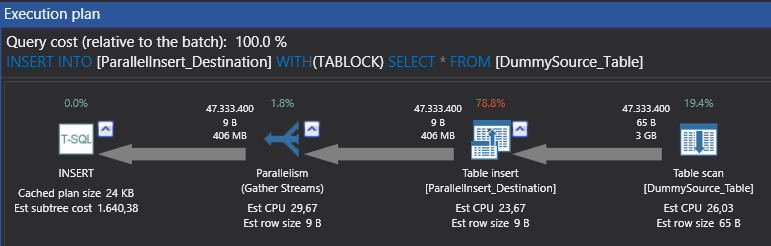
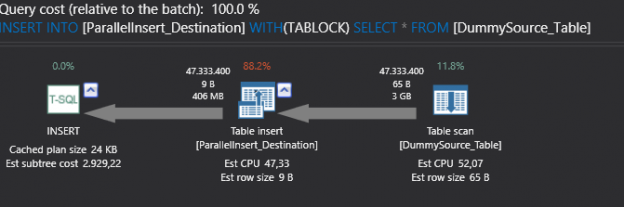
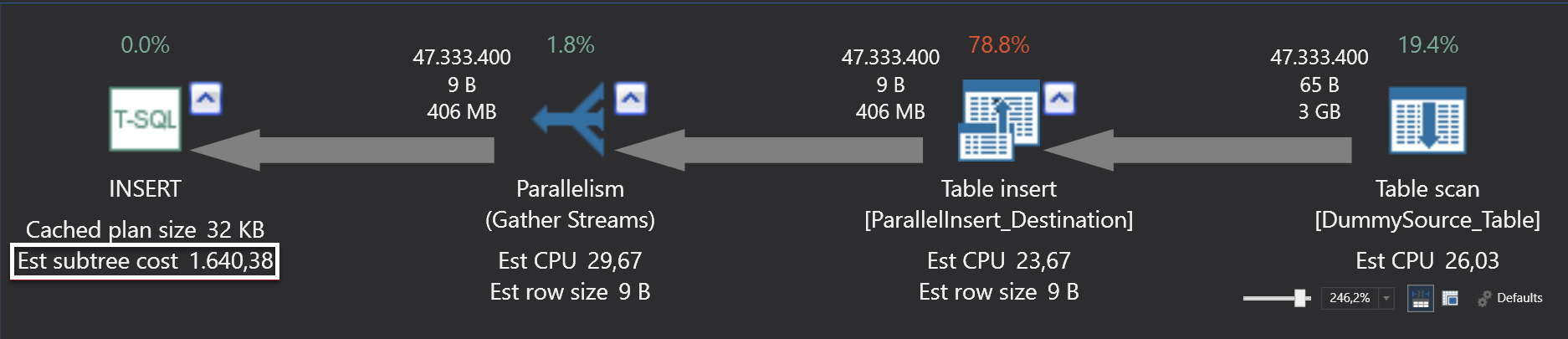
In previous query create parallel execution plan. Left to right it contains:

Parallel table scan operator: this operator indicates SQL Server reads the whole table row by row because we don’t have any index on source table. In the operator properties we can see number of rows read option. This option tells us which thread read how many rows and the parallel option tell us this operator run in parallel
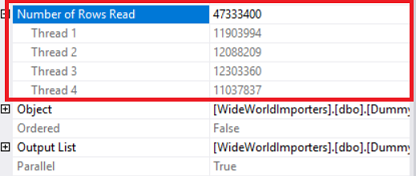

Parallel table insert: this operator indicates parallel insert operations. If we look at the properties of this operator, we can see insert operation distributed to 4 threads


Gather streams: collect parallel operators and convert these operators to single, serial stream. In this operator properties we cannot see any thread distribution

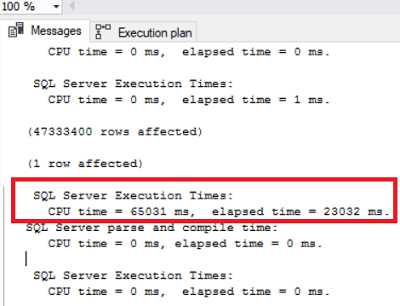
Now we will examine SQL Server execution times.
Cpu time: total processor time which is spent by all processors. We can see this option main execution plan operators.
Elapsed time: total time of query.

| Query Name | CPU Time (ms) | Elapsed Time (ms) | Number of Threads |
| With parallel insert 4 threads | 65031 | 23032 | 4 |
Query estimated subtree cost: this is a unit of measurement system for execution plans.
Cost threshold for parallelism: this option indicates when a query has an estimated cost greater than this value, this query may run in parallel.
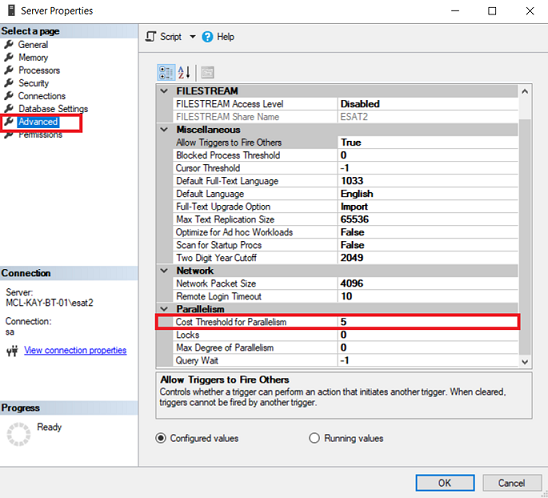
Our previous query estimated subtree cost is 1640. Now we will change cost threshold over 1640 and SQL Server query optimizer generates a serial plan because this value affects the SQL Server query optimizer choice and whether a query execution plan will be parallel or serial.
Now we will change cost threshold option value
|
1 2 3 4 5 6 7 8 9 10 11 |
exec sp_configure 'advanced',1 GO RECONFIGURE GO exec sp_configure 'cost threshold for parallelism', 5000; GO RECONFIGURE GO exec sp_configure 'cost threshold for parallelism' |

|
1 2 3 4 5 6 7 8 |
SET STATISTICS TIME ON TRUNCATE TABLE [ParallelInsert_Destination] SET STATISTICS TIME ON INSERT INTO [ParallelInsert_Destination] WITH(TABLOCK) SELECT * FROM [DummySource_Table] SET STATISTICS TIME OFF |
If we will run previous query. We could not see the parallel operators
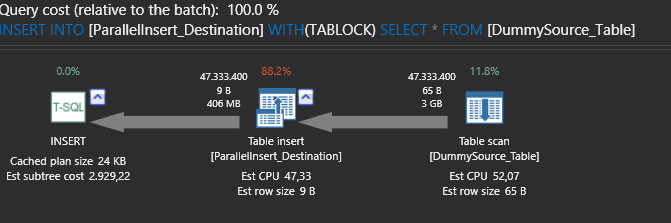
Cost threshold for parallelism option value directly affect SQL Server query optimizer choice.
This query will generate serial execution plan
|
1 2 3 4 5 6 7 8 |
SET STATISTICS TIME ON TRUNCATE TABLE [ParallelInsert_Destination] SET STATISTICS TIME ON INSERT INTO [ParallelInsert_Destination] SELECT * FROM [DummySource_Table] SET STATISTICS TIME OFF |
| Query Name | CPU Time (ms) | Elapsed Time (ms) | Number of Threads |
| With parallel insert 1 thread | 107078 | 111581 | 1 |
This query will generate a 2 thread parallel plan
|
1 2 3 4 5 6 7 8 9 |
SET STATISTICS TIME ON TRUNCATE TABLE [ParallelInsert_Destination] SET STATISTICS TIME ON INSERT INTO [ParallelInsert_Destination] WITH(TABLOCK) SELECT * FROM [DummySource_Table] OPTION (MAXDOP 2) SET STATISTICS TIME OFF |
| Query Name | CPU Time (ms) | Elapsed Time (ms) | Number of Threads |
| With parallel insert 2 threads | 59203 | 33648 | 2 |
This query will generate a 3 thread parallel plan
|
1 2 3 4 5 6 7 8 9 |
SET STATISTICS TIME ON TRUNCATE TABLE [ParallelInsert_Destination] SET STATISTICS TIME ON INSERT INTO [ParallelInsert_Destination] WITH(TABLOCK) SELECT * FROM [DummySource_Table] OPTION (MAXDOP 3) SET STATISTICS TIME OFF |
| Query Name | CPU Time (ms) | Elapsed Time (ms) | Number of Threads |
| With parallel insert 3 threads | 66249 | 24348 | 3 |
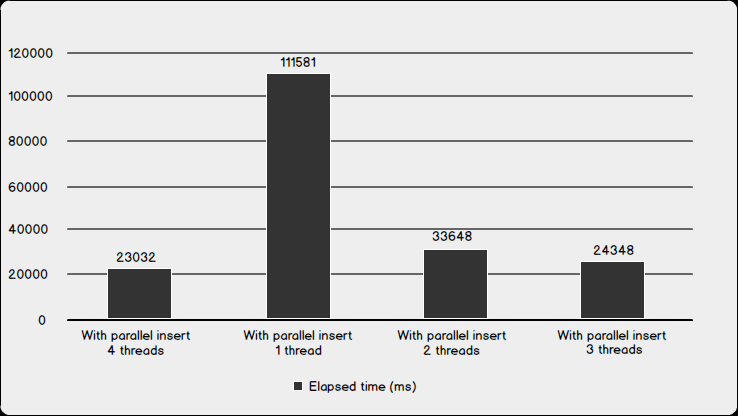
The chart above tells us that parallel insert option creates a significant performance improvement. It reduces the execution time of query.
Limitations
- If the target is a heap table (a table without clustered indexes), a parallel insert execution plan is created by the query optimizer
- Table variables do not allow parallel insert execution plans
- Database compatibility level must be 130 or above
Conclusions
SQL Server parallel insert feature provides high performance on bulk insert operations and ETL process. This feature provides the opportunity for significant performance improvements.
See more
Check out ApexSQL Plan, to view SQL execution plans, including comparing plans, stored procedure performance profiling, missing index details, lazy profiling, wait times, plan execution history and more


Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023