

P1: ¿Cuál es la diferencia entre tabla Montón y tabla Agrupada? ¿Cómo podemos identificar si la tabla es una tabla montón?
Una tabla Montón es una tabla en la cual, las filas de información no están almacenadas en ningún orden en particular en cada página de información. Además, no hay un orden particular para controlar la secuencia de información de página que no está unida en un enlace de lista. Esto es debido al hecho de que la tabla montón no contiene índices agrupados.
Una tabla agrupada es una tabla que tiene un índice agrupado predefinido en una columna o múltiples columnas de la tabla que defina el orden de almacenaje de las filas dentro de las páginas de información y el orden de las páginas dentro de la tabla, basados en el índice agrupado clave.
La tabla montón puede ser identificada al consultar el sistema objeto sys.partitions que tiene una fila por cada partición con el valor index_id igual a 0. Puedes también consultar el sistema objeto sys.indexes para mostrar los detalles de la tabla montón de índices, que muestra que el id de ese índice es 0 y el tipo es MONTON.
Para más información, véase el artículo Resumen de la estructura de la tabla de SQL Server
P2: Explica ¿cómo el Motor SQL Server usa un Mapa de Asignación de Índice (IAM)?
El motor SQL Server usa un Mapa de Asignación de Índice (IAM) para mantener una entrada por cada página para localizar la asignación de esas páginas disponibles. El IAM es considerado como la única conexión lógica entre las páginas de información, que el Motor de SQL Server usará para mover a través del montón.
Para más información, ver el artículo Resumen de la estructura de la tabla de SQL Server.
P3: ¿Qué es el “Problema de Renvío de Punteros” y cómo podemos arreglarlo?
Cuando una operación de modificación de información es realizada en una tabla montón de las páginas de información, Los Renvíos de Punteros serán insertados en el montón para apuntar la nueva localización de la información movida. Estos punteros reenviados causarán problemas de rendimiento en el tiempo debido a visitar las localizaciones antiguas/originales vs las nuevas localizaciones especificadas por los punteros renviados para tener un valor específico.
Empezando de la versión SQL Server 2008, un nuevo método fue introducido para mejorar el problema de rendimiento de punteros renviados, al usar el comando ALTER TABLE REBUILD, que va a reconstruir la tabla montón.
Para más información, ver el artículo Resumen de la estructura de la tabla de SQL Server.
P4: ¿Qué es un índice SQL Server?
Un índice SQL Server es considerado como uno de los factores más importantes en el rendimiento del proceso de optimización. Los índices son creados para hacer más rápida la recuperación de información y las operaciones de procesamiento de consultas de una tabla de base de datos o vista, al proveer rápido acceso a las filas de la tabla de base de datos, sin la necesidad de escanear toda la información de la tabla, para poder recuperar la información requerida.
Puedes imaginar una tabla de índice como un índice de un libro que te permite encontrar la información requerida muy rápido en tu libro, en vez de leer todas las páginas del libro para encontrar un ítem específico que estás buscando.
Para más información, véase el artículo Estructura de índices y conceptos de SQL Server
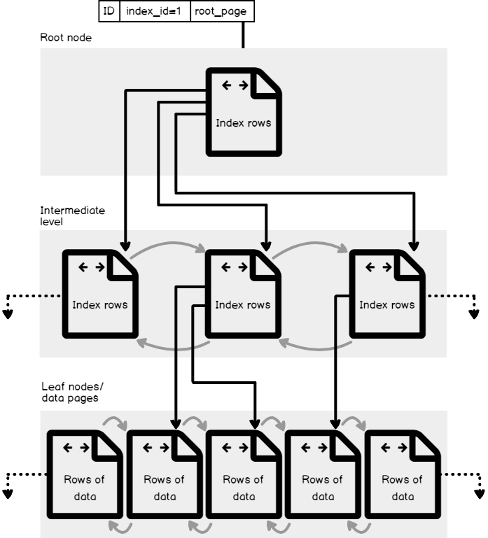
P5: Describe la estructura del Índice SQL Server que provee más rápido acceso a la información de la tabla
Un índice SQL Server es creado usando la forma de estructura B-Árbol, que está compuesta por páginas desde hasta 8K, con cada página, en esa estructura, llamada un índice nodo. La estructura B-Árbol provee al Motor de SQL Server de un modo más rápido de moverse a través de las filas de la tabla basado en un índice clave, que decide navegar a la izquierda o derecha, para recuperar los valores requeridos directamente, sin escanear todas las filas de la tabla subyacente. Puedes imaginar la degradación del rendimiento potencial que puede ocurrir debido a escanear tablas de grande base de datos.
La estructura B-Árbol consiste de los tres niveles principales:
- El nivel Raíz, que es el nodo superior, que contiene una sola página de índice, forma en la cual SQL Server comienza su búsqueda de información.
- El nivel Hoja, el nivel de fondo de los nodos que contiene la información de las páginas que estamos buscando, con el número de páginas hoja que depende de la cantidad de información almacenada en el índice.
- Y finalmente el nivel Intermedio, uno o múltiples niveles entre en nivel raíz y el nivel hoja que contiene los valores del índice clave y los punteros al siguiente nivel de páginas intermedias, o las páginas de información hoja. El número de niveles intermedios depende de la cantidad de información almacenada en el índice.
Para más información, ver el artículo Estructura de índices y conceptos de SQL Server.
P6: Explica los factores de Profundidad de Índice, Densidad, Selectividad y ¿cómo estos factores afectan el rendimiento del índice?
- La Profundidad del Índice es el número de niveles del nodo de la raíz del índice a los nodos hoja. Un índice que es bastante profundo sufrirá del problema de degradación de rendimiento. En contraste, un índice con un gran número de nodos en cada nivel puede producir una estructura de índice muy plana. Un índice con solo 3 a 4 niveles es muy común.
- La densidad del Índice: Es una medida de la falta de singularidad de la información en la tabla. Una columna densa es aquella que tiene un gran número de duplicados.
- La selectividad del índice: es una medida de cuántas filas escaneadas comparadas el total del número de filas. Un índice con alta selectividad significa un número pequeño de filas escaneadas cuando se relaciona con el total de número de filas.
Para más información, ver el artículo Estructura de índices y conceptos de SQL Server.
P7: ¿Cuál es la diferencia entre las cargas de trabajo OLTP and OLAP y cómo afectan a la decisión de creación de índices?
En bases de datos Online Transaction Processing (OLTP), las cargas de trabajo son usadas para sistemas transaccionales en los cuales las consultas subidas son consultas de modificación de información.
En contraste la base de datos Online Analytical Processing (OLAP), las cargas de trabajo son usadas para sistemas de almacenaje de información, en la cual la mayor parte de las consultas subidas son consultas de recuperación de información que filtran, agrupan, agregan y unen grupos grandes de información rápidamente.
Creando un gran número de índices en una tabla de base de datos afecta la modificación de datos (ej. Actualizaciones) operaciones de rendimiento. Cuando añades o modificas una fila en la tabla subyacente, la fila también será ajustada apropiadamente en todas las tablas relacionadas indexadas. Debido a esto, necesitas evitar crear un gran número de índices en las tablas muy modificadas y crear el mínimo número de índices posible, con el menor número posible de columnas en cada índice. Para cargas de trabajo Online Analytical Processing (OLAP), en las cuales las tablas tienen requerimientos bajos de modificación, puedes crear un gran número de índices que mejoran el rendimiento de las operaciones de recuperación de datos.
Para más información, ver el artículo Diseño básico de índices SQL Server y directrices.
P8: ¿Por qué no es recomendado crear índices en tablas pequeñas?
Toma al Motor SQL Server menos tiempo escanear la tabla subyacente que atravesar el índice cuando se busca una información específica. En este caso, el índice no será usado pero todavía va a afectar negativamente el rendimiento de las operaciones de modificación de información, como siempre será ajustado al modificar la información de la tabla subyacente.
Para más información, ver el artículo Diseño básico de índices SQL Server y directrices.
P9: ¿Cuáles son algunas formas diferentes de crear un índice?
- Mediante la declaración CREATE INDEX T-SQL.
- Usar el SQL Server Management Studio, al abrir la tabla en la cual necesitas crear el índice, hacer clic derecho en el nodo de los Índices y escoger la opción New Index.
- Indirectamente al definir la restricción PRIMARY KEY y UNIQUE en las declaraciones CREATE TABLE o ALTER TABLE.
Para más información, ver el artículo Operaciones de índices SQL Server
P10: ¿Cuáles son los pros y contras de usar la creación de índices ONLINE u opciones de reconstrucción?
Configurar la opción ONLINE a ON cuando creas o reconstruyes el índice va a habilitar otros procesos de información recuperada o modificada en la tabla subyacente para continuar, previniendo al proceso de creación del índice de bloquear la tabla. Por otro lado, la creación de índices ONLINE o procesos de reconstrucción tomará más largo tiempo que el proceso de creación de índices offline por defecto.
Para más información véase el articulo Operaciones de índices SQL Server.
P11: ¿Cuál es la diferencia entre PAD_INDEX y FILLFACTOR?
- FILLFACTOR es usado para configurar un porcentaje de espacio libre que el Motor SQL Server va a dejar en el nivel hoja de cada página de índice durante la creación de índice. El factor FillFactor debería ser un valor entero entre 0 a 100, con 0 o 100 como valor defecto, en el cual las paginas serán llenados completamente durante la creación del índice.
- PAD_INDEX es usado para aplicar el porcentaje de espacio libre especificado por el FillFactor para el nivel de página de índices intermedio durante la creación del índice.
Para más información véase el articulo Operaciones de índices SQL Server.
P12: ¿Cuántos índices Agrupados pueden ser creados en una tabla y por qué?
El SQL Server nos permite crear solo un índice Agrupado por cada tabla, mientras la información puede ser clasificada en la tabla usando solo un criterio de orden.
Para más información véase el articulo Diseño efectivo de índices agrupados SQL Server.
P13: Describe las características de un índice clave Agrupado
- Corto: A pesar que el SQL Server nos permite añadir hasta 16 columnas al índice, con un tamaño máximo de 900 bytes, el índice clave agrupado típico es mucho más pequeño de lo que es permitido, con menos columnas posibles. Un índice clave agrupado amplio también afectará a los índices no agrupados construidos sobre ese índice agrupado, ya que el índice clave agrupado será usado como clave lookup para todos los índices no agrupados apuntando a él.
- Estático: Es recomendado para escoger columnas que no están cambiadas frecuentemente en un índice clave agrupado. Cambiando el índice clave agrupado significa que la fila entera será movida a la nueva página para mantener la información de los valores en el correcto orden.
- Incremental: Usando una columna incremental (aka incrementing), como la columna IDENTITY, mientras un índice agrupado clave ayudará a mejorar el proceso INSERT, que va a directamente inserta los nuevos valores en la parte lógica final de la tabla. Esta opción muy recomendada ayudará a reducir la cantidad de memoria requerida para la página búfer, minimiza la necesidad de dividir la página en dos páginas para hacer entrar los nuevos valores insertados y la ocurrencia de fragmentación, que requería reconstruir o reorganizar el índice otra vez.
- Único: Es recomendado declarar la columna de índice agrupado clave o combinación de columnas como única para mejorar el rendimiento de las consultas. De otro modo el SQL Server va a automáticamente añadir a unificar la columna para aplicar la singularidad del índice agrupado clave.
- Accedido frecuentemente: Esto es debido al hecho de que las filas estarán almacenadas en el índice agrupado en un orden clasificado basado en el índice clave que es usado para acceder la información.
- Usado en la cláusula ORDER BY: En este caso, no hay necesidad del Motor de SQL Server para ordenar la información para mostrarla, ya que las filas están ya ordenadas basadas en los índices clave usados en la cláusula ORDERBY
Para más información véase el articulo Diseño efectivo de índices agrupados SQL Server.
P14: ¿Por qué no es recomendado usar columnas GUID y columnas CHARACTER como índices clave Agrupados?
Para columnas GUID, que están almacenadas en las columnas UNIQUE IDENTIFIER, el principal desafío que afecta el rendimiento de la clasificación del índice agrupado clave, es la naturaleza del valor GUID que es más largo que los tipos enteros de información, con 16 bytes de tamaño, y que es generada en una manera aleatoria, diferentes del valor entero IDENTITY que están aumentando continuamente.
Para las columnas de CHARACTER. Los principales desafíos incluyen rendimiento de clasificación limitada de los tipos de información carácter, el gran tamaño, los valores no incrementales, valores no estáticos que a menudo tienden a cambiar en las aplicaciones de negocios y no comparados como valores binarios durante el proceso de clasificación, ya que el mecanismo de comparación de caracteres depende de la colación usada.
Para más información véase el articulo Diseño efectivo de índices agrupados SQL Server.
P15: ¿Cuál es la principal diferencia entre una estructura de índice Agrupado y No Agrupado?
Un índice No agrupado es diferente de un índice Agrupado en que las filas de la tabla subyacente no serán almacenadas y clasificadas basados en la clave No Agrupada, y que los nodos del nivel hoja del índice No agrupado están hechos con páginas índices en vez de páginas de información. Las páginas de información de los índices No agrupados contienen valores de índices clave No agrupados con punteros hacia la localización de almacenaje de estas filas en las tablas montón subyacentes o en el índice Agrupado.
Para más información véase el articulo Diseño efectivo de índices no agrupados SQL Server.
P16: ¿Cuál es la principal diferencia entre un índice No agrupado que es construido en una tabla Montón y un índice No agrupado construido en una tabla Agrupada? Cuál es la diferencia entre un RID Lookup y un Key Lookup?
Si un índice No Agrupado es construido sobre una tabla Montón o vista (lee más sobre vistas de Índices SQL Server, que no tienen índices Agrupados) los nodos del nivel hoja de ese índice guardan valores de índice clave y punteros ID de fila (RID) a las localizaciones de las filas en la tabla montón.
El RID Consiste en el identificador de archivo, el número de página de la información, y el número de filas en esa página de información.
Por otro lado, si un índice No agrupado es creado sobre una tabla Agrupada, los nodos del nivel hoja de ese índice contienen valores de índices clave No agrupados y claves agrupadas par la tabla base, que son las localizaciones de las filas en las páginas de información de índices Agrupados.
Las operaciones de RID Lookup son realizadas para recuperar el resto de la columnas que no están disponibles en el índice de la tabla montón basadas en el ID de cada fila.
Una operación Key Lookup es realizada para recuperar el resto de las columnas que no están disponibles en el índice del índice Agrupado, basado en la clave Agrupada de cada fila.
P17: ¿Cómo nos podemos beneficiar de la característica de INCLUDE para mejorar las limitaciones del índice No Agrupado?
En vez de crear un índice No agrupado con una clave amplia, grandes columnas que son usadas para cubrir la consulta pueden ser incluidas en el índice No agrupado como columnas no-clave, hasta 1023 columnas no-clave, usando la cláusula INCLUDE de la declaración CREATE INDEX T-SQ, que fue introducida en el SQL Server 2005, con un mínimo de una columna clave.
La característica INCLUDE extiende la funcionalidad de los índices No agrupados, al permitirnos cubrir más consultas al añadir las columnas como columnas no-clave para ser almacenadas y clasificados solo en nivel hoja del índice, sin considerar esos valores de las columnas en los niveles raíz e intermedios de los índices No agrupados. En este caso, el Optimizador de Consultas de SQL Server va a localizar todas las columnas requeridas de ese índice, sin la necesidad de extra lookups. Usando las columnas incluidas puede ayudar a evitar exceder el límite de tamaño de No Agrupados de 900 bytes y 16 columnas en el índice clave, mientras que el Motor SQL Server Database no considera las columnas del índice No agrupado no-clave cuando se calcula el tamaño y el número de columnas del índice clave. Además, El SQL Server nos permite incluir las columnas con los tipos de información que no son permitidas en el índice clave, como VARCHAR(MAX), NVARCHAR(MAX), text, ntext e image, como columnas de índices No agrupados no-clave.
Para más información véase Índices no agrupados de SQL Server con columnas incluidas.
P18: ¿Qué tipo de índices son usados para mantener la integridad de la información de las columnas en las cuales son creadas?
Índices únicos, al asegurar que no hay valores duplicados en ese índice clave y en las filas de tabla, en el cual ese índice es creado.
Para más información, ver el artículo Uso de diferentes tipos de índices SQL Server.
P19: ¿Cómo nos podemos beneficiar del índice Filtrado al mejorar el rendimiento de nuestras consultas?
Usa un predicado de filtro para mejorar el rendimiento de las consultas que recuperan un subconjunto bien definido de filas de la tabla, al indexar la única porción de la fila de tablas. El tamaño más pequeño de los índices Filtrados, que consume una pequeña cantidad del espacio del disco comparado con el tamaño del índice de tabla entera, y las más precisas estadísticas filtradas, que cubren las filas del índice filtrado con solo costo mínimo de mantenimiento, ayuda a mejorar el rendimiento de las consultas al general un plan más óptimo de ejecución.
Para más información ver el artículo: Uso de diferentes tipos de índices SQL Server.
P20: ¿Cuales son las formas diferentes que pueden ser usadas para recuperar las propiedades de las columnas participando en un índice SQL Server?
- Usando SSMS, al expandir los nodos de Índices bajo una tabla de base de datos, luego hacer clic derecho en cada índice, y escoger la opción Propiedades. El problema con obtener la información de los índices usando el método UI es que necesitas abrir un índice a la vez por cada tabla. Puedes imaginar el esfuerzo requerido para ver el artículo: Todos los índices en una específica base de datos.
- El Sistema de procedimiento de almacenado sp_helpindex, al proveer el nombre de la tabla que necesitas listar sus índices. Para obtener información sobre todos los índices en una específica base de datos, necesitas ejecutar el número sp_helpindex de tiempo igual a el número de tablas en tu base de datos.
- La vista de sistema administración dinámica sys.indexes. El sys.indexes contiene una fila por cada índice en la tabla o vista. ES recomendable unir sys.indexes DMV con otros sistemas DMVs, como las columnas sys.index_columns, sys.columns y sys.tables para retornar información significante sobre estos índices.
Para más información ver el artículo: Obtener estadísticas de índices y uso de información SQL Server
P21: ¿Cómo podemos tener porcentaje de fragmentación de una base de datos de índice?
- Usando SSMS, de la pestaña de Fragmentación de la venta de Propiedades del índice. Verificar el porcentaje de fragmentación de todos los índices en una base de datos específica, usando el método UI requiere un gran esfuerzo, ya que necesitas verificar un índice a la vez.
- La función dinámica de administración sys.dm_db_index_physical_stats, que fue primeramente introducida en el SQL Server 2005. El sys.dm_db_index_physical_stats DMF puede ser unido con el sys.indexes DMV para retornar el porcentaje de fragmentación de todos los índices bajo la base de datos especificada.
Para más información, ver el artículo: Obtener estadísticas de índices y uso de información SQL Server
P22: Cuando se verifica la información estadística del uso del índice, recuperado por consultar la vista de administración dinámica sys.dm_db_index_usage_stats, explica los resultados del número de búsquedas, escaneos, consultas y actualizaciones retornadas.
- El número de Búsquedas indica el número de veces que el índice es usado para encontrar una fila específica.
- El número de Escaneos muestra el número de veces que las páginas hoja del índice son escaneadas.
- El número de Consultas indica el número de veces que un índice Agrupado es usado por un índice No agrupado para buscar la fila completa.
- Y el número de Actualización muestra el número de veces que la información del índice ha sido modificada.
Para más información, ver el artículo: Obtener estadísticas de índices y uso de información SQL Server
P23: ¿Cuál es la diferencia entre operaciones de índice Reconstruido e Índice Reorganizado?
La fragmentación de índice puede ser resuelta al reconstruir y reorganizar los Índices SQL Server regularmente. Las operaciones de Reconstrucción de Índice remueve la fragmentación al abandonar el índice y crearlo de nuevo, desfragmentando todos los niveles de índices, compactando las páginas de índices usando los valores FillFactor especificados en el comando rebuild, o usando el valor existente si no es especificado y actualizando las estadísticas de índice usando FULLSCAN de toda la información.
Las operaciones de Reorganizar, reordena físicamente las páginas de nivel hoja de los índices para corresponder el orden lógico de los nodos hoja. La reorganización del índice siempre será realizada online. Microsoft recomienda arreglar los problemas de fragmentación de índice al reconstruir el índice si el porcentaje de fragmentación del índice excede el 30 %, donde se recomienda arreglar el problema de fragmentación del índice al reorganizar el índice si el porcentaje de fragmentación del índice excede el 5 % y menos del 30 %.
Para más información, ver el artículo: Mantenimiento de índices SQL Server
P24: ¿Cómo puedes encontrar los índices perdidos que son necesitados para mejorar potencialmente el rendimiento de nuestras consultas?
- La opción Missing Index Details en el plan de ejecución de consulta, si está disponible.
- La vista de administración dinámica sys.dm_db_missing_index_details, que retorna información detallada sobre índices perdidos, índices espaciales excluidos.
- Una combinación de las herramientas SQL Server Profiler y el Database Engine Tuning Advisor.
Para más información, ver el artículo: Seguimiento y optimización de consultas utilizando índices SQL Server
P25: ¿Por qué un índice es descrito como una espada de doble filo?
Un índice bien definido va a mejorar el rendimiento de tu sistema y hacer más rápido el proceso de recuperación de información. Por el otro lado, un índice mal diseñado causará degradación del rendimiento en tu sistema y te costara espacio extra del disco y retardará la inserción de la información y operaciones de modificación. Es mejor siempre probar el rendimiento del sistema antes y después añadir el índice el ambiente de desarrollo, antes de añadirlo al ambiente de producción.
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.



He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019