

En los artículos previos de estas series (véase el artículo completo TOC en la parte de abajo), hemos discutido la estructura interna de las tablas SQL Server e índices, las mejores prácticas para seguir cuando se diseña un índice apropiado, el grupo de operaciones que puedes realizar en los índices SQL Server , cómo diseñar efectivos índices Agrupados y No agrupados y finalmente los diferentes tipos de índices SQL Server, por encima y más allá de la clasificación de índices Agrupados y No agrupados. En este artículo, vamos a discutir cómo ajustar el rendimiento de las malas consultas usando Índices SQL Server.
Hasta este punto, después de obtener un completo entendimiento del concepto de estructuras de índices SQL Server, diseño y tipos, estamos listos para diseñar los más efectivos índices SQL Server del cual el Optimizador de Consultas SQL Server siempre tomará beneficios, al hacer más rápido el proceso de recuperación de información en nuestras consultas, lo cual es el principal objetivo de crear un índice, con el mínimo de operaciones de disco I/O el menos uso de los recursos del sistema.
Antes de diseñar un índice, que ayuda al procesador de consultas encontrar la información rápidamente y tocar la tabla subyacente las menos veces posible, deberías tener buen entendimiento de la estructura de información subyacente y su uso, el tipo de consultas leyendo esa información y la frecuencias de las consultas corridas. Como administrador de la base de datos, puedes usar diferentes herramientas y scripts para proveer a los dueños del sistema con la lista de índices sugeridos que pueden mejorar el rendimiento de la consulta de su sistema. Pero dependiendo de su entendimiento del comportamiento del sistema, deberían proveer la confirmación final de crear aquellos índices, solo después de examinar el rendimiento de las consultas en el desarrollo del ambiente antes y después de crear los índices sugeridos.
Los administradores de base de datos tienen que hacer un balance entre crear muchos índices y muy pocos índices. Por ejemplo, no hay necesidad de poner índice en cada columna individualmente o envolver la columna con muchos índices sobrepuestos. Deberían también tomar en consideración que, el índice que va a mejorar el rendimiento de las consultas SELECT va a también hacer más lentas las operaciones DML, como las consultas INSERT, UPDATE, y DELETE.
Otra cosa a considerar es el ajuste de los índices mismos, ya que el índice que está trabajando bien con tus consultas en el pasado, pueda no cumplir con las consultas ahora, debido a cambios frecuentes en el esquema de la tabla y la información misma. Esto puede requerir remover el índice y crear uno más efectivo. Vamos a discutir en detalle en el siguiente artículo, cómo obtener información sobre el uso de los índices y decidir si necesitamos mantener o remover ese índice. Por otro lado, el índice puede estar sufriendo de problemas de fragmentación, solamente debido a cambiar la información frecuentemente, que puede ser resuelto usando las tareas de mantenimiento de índice, discutidas profundamente en el anterior artículo de estas series.
Déjanos empezar nuestra demo para entender el concepto de ajuste de rendimiento de manera práctica. Hemos creado una nueva base de datos, IndexDemoDB, que contiene tres tablas; la tabla STD_Info que contiene la información de los estudiantes, la tabla de Cursos que contiene la lista de los cursos disponibles y finalmente la tabla STD_Evaluation contiene dos claves extranjeras; el ID del estudiante que referencia la tabla STD-Info y el ID del curso que referencia a la tabla Cursos. El script T-SQL de abajo es usado para crear la base de datos y las tablas como descrito:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE DATABASE IndexDemoDB GO CREATE TABLE STD_Info ( STD_ID INT IDENTITY (1,1) PRIMARY KEY, STD_Name VARCHAR (50), STD_BirthDate DATETIME, STD_Address VARCHAR (500) ) GO CREATE TABLE Courses ( Course_ID INT IDENTITY (1,1) PRIMARY KEY, Course_Name VARCHAR (50), Course_MaxGrade INT ) GO CREATE TABLE STD_Evaluation ( EV_ID INT IDENTITY (1,1), STD_ID INT, Course_ID INT, STD_Course_Grade INT, CONSTRAINT FK_STD_Evaluation_STD_Info FOREIGN KEY (STD_ID) REFERENCES STD_Info (STD_ID), CONSTRAINT FK_STD_Evaluation_Courses FOREIGN KEY (Course_ID) REFERENCES Courses (Course_ID) ) |
Una vez que la base de datos y las tablas son creadas, sin índice o clave definidos en la tabla STD_Evaluation, vamos a llenar cada tabla con 100 mil registros, usando ApexSQL Generate como se muestra abajo:

Ajustando una consulta simple
Leer una tabla que no tiene índice es similar a encontrar una palabra en un libro al examinar cada página en ese libro. Si tratas de ejecutar la consulta de abajo SELECT para recuperar la información de la tabla STD_Evaluation, después de habilitar las estadísticas TIME IO e incluir el plan de ejecución, usando la declaración T-SQL de abajo.
|
1 2 3 4 |
SET STATISTICS TIME ON SET STATISTICS IO ON GO SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
Verás del plan de ejecución, generado después de ejecutar la consulta que el SQL Server realizará operaciones de Escaneo de Tabla sobre la tabla al examinar todas las filas de la tabla para verificar si estas filas cumple con la condición WHERE, como se muestra en el plan de ejecución de abajo:

Puedes ver también de las estadísticas TIME e IO, que la consulta es ejecutada con 655 ms consumiendo 94 ms del tiempo de CPU, como se muestra abajo:

Teniendo un índice en la parte frontal del libro, permitirá al lector encontrar su objetivo más rápido. Lo mismo se aplica en las tablas SQL Server, teniendo un índice en la tabla, hará más rápido el proceso de recuperación de información, proveyendo al cliente la información requerida en un corto tiempo, claro si el índice es diseñado apropiadamente.
Si vemos en la superficie la consulta previa SELECT y decidimos añadir un índice en la columna STD_ID mencionada en la cláusula WHERE de esa consulta, usando la declaración CREATE INDEX T-SQL de abajo:
|
1 |
CREATE NONCLUSTERED INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] (STD_ID) |
Luego ejecutamos la misma declaración SELECT:
|
1 |
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
Verás del plan de ejecución, generado después de ejecutar la consulta, que el SQL Server realiza otra vez operaciones de Escaneo de Tabla, para recuperar la información de la tabla, sin considerar el índice creado, como se muestra en el plan de ejecución de abajo.

Verificando las estadísticas TIME e IO de la consulta, verás que, el tiempo requerido, y el tiempo de consumo de CPU para ejecutar la consulta no está muy lejos de la declaración previa SELECT sin índices, con pequeñas mejoras mostradas abajo:

Teniendo un índice creado en esa tabla no significa que el SQL Server lo usará necesariamente. En algunas situaciones, el SQL Server encuentra que escanear la tabla subyacente es más rápido que usar el índice, especialmente cuando la tabla es pequeña, o la consulta retorna la mayor parte de los registros de la tabla.
Déjanos dar una segunda mirada al plan de ejecución previo, verás un mensaje verde del SQL Server que recomienda un índice para mejorar el rendimiento en esa consulta en 77.75 %. Apreta clic derecho en ese plan de ejecución y escoger la opción Missing Index Details, para mostrar el índice sugerido, como se muestra abajo:

La misma sugerencia de índice puede ser encontrada al consular la vista dinámica de administración sys.dm_db_missing_index_details , que retorna información detallada sobre índices perdido, índices espaciales excluidos, como se muestra abajo:
|
1 |
SELECT * FROM sys.dm_db_missing_index_details |
La consulta previa sugerirá el mismo índice utilizado, con el STD_ID que es usado en la cláusula WHERE de la consulta como un índice clave y el resto de las columnas retornadas en la declaración SELECT, las columnas EV_ID, Course_ID y STD_Course_Grade, como columnas no-clave en la cláusula INCLUDE de la declaración de creación de índice mostrada abajo:

Quitaremos el índice malo creado previamente y crearemos un nuevo índice que es sugerido por el SQL Server usando el script T-SQL de abajo:
|
1 2 3 4 5 6 7 8 |
USE [IndexDemoDB] GO DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_STD_ID] ON [dbo].[STD_Evaluation] ([STD_ID]) INCLUDE ([EV_ID],[Course_ID],[STD_Course_Grade]) GO |
Si tratas de ejecutar la misma declaración SELECT:
|
1 |
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
Luego verifica el plan de ejecución, generado después de ejecutar la consulta, verás que el SQL Server realizará una operación de Búsqueda de Índice para recuperar la información al usuario, como se muestra abajo:

Las estadísticas TIME e IO mostrarán que el tiempo requerido para ejecutar la consulta decreció de 655 ms a 554 ms, con cierta mejora de 15% después de añadir el índice, y el consumo de tiempo de CPU redujo de 94 ms a 31 ms, con cerca de 67% de mejoramiento cuando se usa el índice. Puedes imaginar el mejoramiento que puede ser ganado en el caso de tablas grandes, como se muestra abajo:

El índice previo No agrupado es creado sobre una tabla montón. Vamos a abandonar el índice No agrupado creado, crear un índice Agrupado en la columna EV_ID, luego crear el índice No agrupado otra vez, usando el script T-SQL de abajo:
|
1 2 3 4 5 6 7 |
DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO CREATE CLUSTERED INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] ([EV_ID]) GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_STD_ID] ON [dbo].[STD_Evaluation] ([STD_ID]) INCLUDE ([EV_ID],[Course_ID],[STD_Course_Grade]) |
Recuerda lo que mencionamos en los artículos previos de estas series que el índice No agrupado será reconstruido automáticamente cuando se crea un índice Agrupado en la tabla para poder apuntar a la clave Agrupada, en vez de apuntar a la tabla base. Si ejecutamos la misma declaración SELECT otra vez:
|
1 |
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
Verás que la misma ejecución de plan será creado sin ningún cambio del anterior, como se muestra abajo:

Además las estadísticas TIME e IO mostrarán que el tiempo requerido para ejecutar la consulta y el tiempo de CPU consumido por la consulta es de algún modo similar al resultado previo, con un pequeño mejoramiento al reducir las operaciones IO realizadas para recuperar la información, debido a trabajar con una tabla más pequeña, como se muestra abajo:

Podrías también pensar en remplazar el índice No agrupado con un índice Agrupado en la columna STD_ID, tomando en consideración que el índice Agrupado no contiene una cláusula INCLUDE. Si abandonamos todos los índices disponibles en esa tabla y la remplazamos por un índice Agrupado, usando el script T-SQL de abajo:
|
1 2 3 4 5 |
DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO DROP INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] GO CREATE CLUSTERED INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] ([STD_ID]) |
Luego se ejecuta la misma sentencia SELECT:
|
1 |
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
Verás del plan de ejecución generado, que la operación de Búsqueda de Índice Agrupado será realizada para recuperar la información requerida, como se muestra abajo:

Con ningún mejoramiento notable en las estadísticas de TIME e IO, generada al ejecutar la consulta, en el caso de nuestra tabla pequeña, como se muestra abajo:

Ajustando una consulta compleja
Déjanos tratar ahora de ajustar e rendimiento de una consulta más compleja, que retorna el nombre del estudiante, el nombre del curso, el máximo grado del curso y finalmente el grado del estudiante en ese grado, al unir las tres tablas previamente creadas juntas, basado en las columnas comunes entre cada dos tablas, tomando en consideración que la tabla STD_Evaluation no tiene índice en ellas, como se muestra en la declaración SELECT de abajo:
|
1 2 3 4 5 6 7 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 |
Si verificas el plan de ejecución generado después de ejecutar la consulta, verás que, debido al hecho de que la Evaluación STD no tiene índice, el SQL Server va a escanear todos los registros de tablas de Evaluación STD para buscar las filas que cumplan con la condición WHERE, al realizar una operación de Escaneo de la Tabla. Además, un mensaje verde será mostrado en el plan de ejecución mostrando un índice sugerido del SQL Server para mejorar el rendimiento de la consulta, como se muestra abajo:

Apretar clic derecho en ese plan de ejecución y escoge la opción Missing Index Details, para mostrar el índice sugerido. La declaración T-SQL que es usada para crear el nuevo índice, con el mejoramiento del rendimiento, el cual es 82 % aquí, será mostrada en la ventana que aparece, como se muestra abajo:

Las estadísticas TIME e IO generadas de ejecutar las consultas previas muestra que el SQL Server realiza 310 lecturas lógicas, con 65 ms y consume 16ms del tiempo de CPU para recuperar la información como se muestra abajo:

La misma sugerencia de índice puede ser también encontrada al consultar la vista dinámica de administración sys.dm_db_missing_index_details, que retorna información detallada sobre índices perdidos, índices espaciales excluidos, como se muestra abajo:

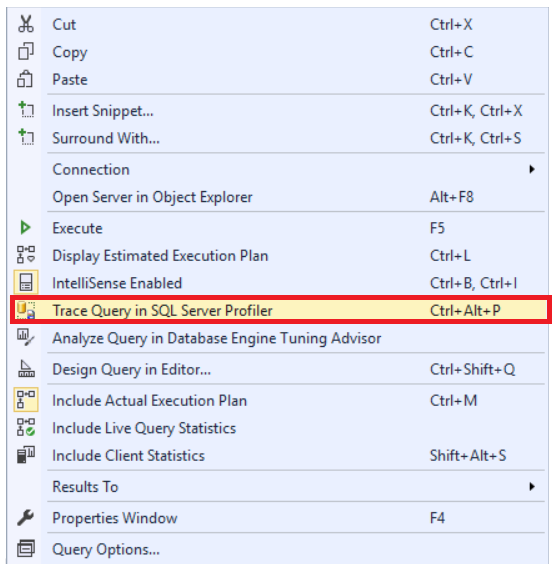
El rendimiento de la consulta puede también ajustada usando la comunicación del SQL Server Profiler y las herramientas Database Engine Tuning Advisor. Apretar clic derecho en la consulta que administras para ajusta y hacer clic en la opción Trace Query in SQL Server Profiler , como se muestra abajo:

Una nueva sesión de SQL Server Profiler será mostrada. Cuando ejecutas la consulta para ser optimizada, la estadística de consultas será capturada en la sesión SQL Server Profile, como se muestra en la captura de pantalla de abajo:

Salva el trazado previo para usarlo como carga de trabajo del Database Engine Tuning Advisor. Del menú de Tools de SQL Server Manager Studio, escoge la opción Database Engine Tuning Advisor, como se muestra abajo:

De la ventana abierta de Database Engine Tuning Advisor, conéctate al target de SQL Server, la base de datos de la cual la consulta será recuperada y finalmente asigna la carga de trabajo del archivo que contiene la marca de consulta, luego apretar clic en
 como se muestra abajo:
como se muestra abajo:

Una vez que la operación de análisis es completada exitosamente, recomendaciones que incluyen índices y estadísticas que pueden mejorar el rendimiento de la consulta, con el porcentaje de mejoramientos estimados será mostrado en el reporte general. En nuestro caso, el mismo índice previo sugerido será mostrado en el reporte de recomendaciones, como se muestra abajo:

Si tomamos la declaración CREATE INDEX provista del plan de ejecución previo, o del reporte Database Engine Tuning Advisor y creamos el índice sugerido para mejorar el rendimiento de consultas, como la declaración T-SQL de abajo:
|
1 2 3 4 5 6 |
USE [IndexDemoDB] GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] ([STD_ID],[Course_ID]) INCLUDE ([STD_Course_Grade]) GO |
Luego se ejecuta la misma sentencia SELECT:
|
1 2 3 4 5 6 7 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 |
Verás el plan de ejecución generado, que la operación de Escaneo lento de Tabla previo cambió a una operación de Búsqueda rápida de Índice, como se muestra abajo:

Las estadísticas TIME e IO también muestran que, después de crear el índice sugerido, el SQL Server realiza solo 3 operaciones lógicas de lectura, comparado a 310 lecturas lógicas antes de crear el índice, con cerca de 91 % de mejoramiento, con 40 ms comparada con 65 ms requeridos para ejecutar la consulta antes de crear el índice, con cerca de 39% de mejoramiento, y no consume tiempo de CPU comparado con los 16ms consumidos antes de crear el índice, como se muestra claramente abajo:

El índice No agrupado previo es creado sobre una tabla montón. Vamos a abandonar el índice No agrupado previamente creado, creando un índice Agrupado, en la columna EV_ID, luego crear el índice No agrupado otra vez, usando el script T-SQL de abajo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE [IndexDemoDB] GO DROP INDEX [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] GO CREATE CLUSTERED INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] ([EV_ID]) GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] ([STD_ID],[Course_ID]) INCLUDE ([STD_Course_Grade]) GO |
Si ejecutas la misma declaración SELECT:
|
1 2 3 4 5 6 7 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 |
El mismo plan de ejecución será generado como se muestra abajo:

Además las estadísticas TIME e IO mostrarán una pequeña mejora en las lecturas lógicas numéricas y el tiempo requerido para ejecutar la consulta, como estamos trabajando con una tabla pequeña, como se muestra abajo:

En los artículos previos de estas series, mencionamos que el orden de clasificación de las columnas en un índice clave debería corresponder al mismo orden de las columnas en la consulta que el índice va a cubrir. Para entender la razón en términos prácticos, déjanos realizar los siguientes dos ejemplos.
En el índice previamente creado, el orden de clasificación de las columnas STD_ID y Course_ID es el orden por defecto ascendente ASC. Si modificamos la consulta SELECT para clasificar las filas retornadas basadas en las columnas en orden descendente DESC STD_ID y Course_ID, lo cual es totalmente opuesto al orden de las columnas en el índice, como se muestra en la consulta T-SQL de abajo:
|
1 2 3 4 5 6 7 8 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 ORDER BY ST.[STD_ID] DESC,C.[Course_ID] DESC |
Verás del plan de ejecución generado, que nada va a ser cambiando excepto por el Scan Direction del índice No Agrupado que va a estar Inverso, que puede ser visto desde la ventana de propiedades de búsqueda de nodos de Índices. Esto significa que, en vez de leer el índice desde arriba hasta abajo, el SQL Server va a leer la información de ese índice desde abajo hasta arriba, sin la necesidad de clasificar la información otra vez, como se muestra claramente abajo:

Con el mínimo costo inverso de lectura, las estadísticas son mostradas abajo:

Las cosas serán diferentes cuando se modifica la consulta para recuperar las filas en un orden que es muy lejano del orden de clasificación en el índice clave. Por ejemplo, si modificamos la consulta SELECT para recuperar información clasificada basada en la columna STD_ID en orden ASC y basado en la columna Course_ID en orden DESC, como se muestra en la declaración T-SQL de abajo:
|
1 2 3 4 5 6 7 8 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 ORDER BY ST.[STD_ID] ASC,C.[Course_ID] DESC |
El SQL server no puede derivar beneficios del orden de clasificación de las columnas en el índice, como es muy lejano del orden requerido en la consulta, pero todavía puede beneficiarse del índice para recuperar información, usando la operación de Búsqueda de índice, después debería ordenar las filas retornadas del índice usando la operación cara de Sort, como se muestra en el plan de ejecución generada abajo:

Puedes ver de las estadísticas TIME, que la operación costosa de Sort va a hacer más lenta la ejecución de la consulta en una cantidad notable. Es por esto que seguimos diciendo que es realmente importante hacer compatible el orden de clasificación de las columnas en el índice y la consulta que sacará beneficios del índice. El costo de tiempo extra de la operación Sort es mostrada claramente abajo:

Es importante mencionar aquí que, indexar las columnas individualmente, tal vez no sea la solución óptima para mejorar el rendimiento de la consulta. Asuma que planeamos indexar ambas columnas STD_ID y Course_ID que son usadas en las condiciones WHERE y JOIN en las consultas previas, tomando en consideración que la tabla STD_Evaluation no tiene índice creado en ella, usando el script T-SQL de abajo:
|
1 2 3 4 5 6 |
CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_STD_ID] ON [dbo].[STD_Evaluation] ([STD_ID]) GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] (Course_ID) GO |
Si ejecutas la misma declaración SELECT:
|
1 2 3 4 5 6 7 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 |
Verás del plan de ejecución generado después de ejecutar la consulta que, los índices creados no cubren la consulta previa, que requiere que el SQL Server realiza una operación extra de Key Lookup para recuperar las columnas restantes que no son incluidas en los índices creados de la tabla base, como se muestra abajo:

Y el caro costo de la operación Key Lookup será traducida en costo extra TIME como se muestra en las estadísticas de abajo:

En este artículo, traducimos los consejos de diseño de índice y trucos mencionados en artículos previos de estas series en términos prácticos. Sigue sintonizado para el siguiente artículo, donde vamos a verificar la información del índice para mantener índices útiles y abandonar los malos.
Tabla de contenido
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.



He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019