

En los artículos previos de éstas series, Estructura y Conceptos de Índice SQL Server, describimos en detalle la anatomía de los índices de SQL Server, las estructuras B-Árbol, las propiedades de los índices, los principales tipos de índices y las ventajas de usar los índices para sintonización de rendimiento.
Puedes recordar cómo describimos los índices previamente como una espada de doble filo, donde tú puedes sacar beneficios significantes de un índice, que está bien diseñado, al mejorar el rendimiento de tus operaciones de recuperación de información. Por otro lado, un índice pobremente diseñado, o la falta de índices necesarios, causarán la degradación del rendimiento en tu sistema. En este artículo, vamos a ir a través de lo básico y las mejores prácticas que te ayudarán en el diseño de los índices más efectivos para cumplir los requerimientos de tu sistema con la posibilidad de mejoramientos en el rendimiento.
La decisión de escoger el índice correcto que se ajuste en la carga de trabajo del sistema, no es una fácil tarea, ya que necesita compromiso entre la velocidad de las operaciones de recuperación de la información y los costos de añadir ese índice en la operación de modificación de datos. Otro factor que afecta en la decisión de diseño de índice es la lista de columnas que participará en la clave de índice, donde debes tomar en consideración que, más columnas incluidas en la clave de índice para cubrir tu aplicación de consultas, requerirá más espacio en el disco y costos de mantenimiento extra. Necesitas también asegurar que, cuando creas la tabla de índice, el Optimizador de Consultas de SQL Server va a escoger los índices creados para recuperar información de la tabla en la mayoría de los casos. La decisión de usar el Optimizador de Consultas de SQL Server depende de la mejora del rendimiento que se tomara del uso de ese índice.
Tipo de carga de trabajo
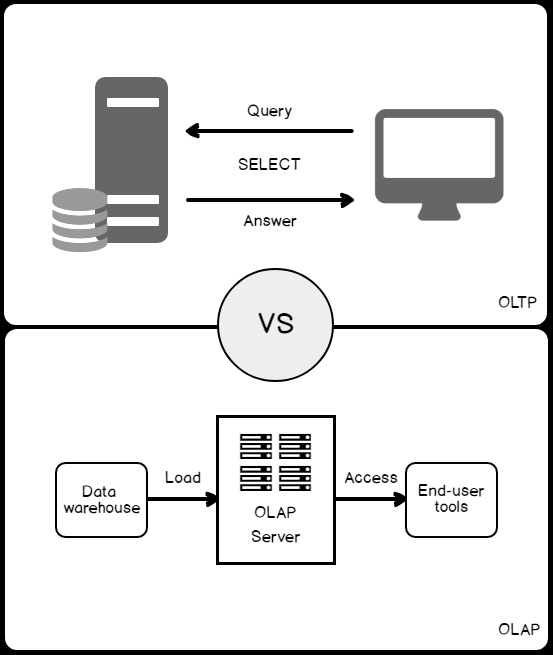
Antes de crear un índice, deberías entender el tipo de carga de trabajo de la base de datos. En la base de datos del Procesamiento Transaccional Online (OLTP), las cargas de trabajo son usadas para sistemas transaccionales en los cuales, la mayoría de las consultas presentadas son consultas de modificación de información. En cambio, las cargas de trabajo de la base de datos del Procesamiento Analítico Online (OLAP) son usadas para sistemas de almacenamiento de información, en los cuales la mayoría de las consultas presentadas son consultas de recuperación de información que filtra, agrupa, agrega y une grupos grandes de información rápidamente. La diferencia entre las bases de dato OLTP y el OLAP pueden ser resumida en la figura de abajo:

Creando un gran número de índices en una tabla de base de datos afecta en el rendimiento de las operaciones de modificación de la información (ej. Actualizaciones). Cuando añades o modificas una fila en la tabla subyacente, la fila también será ajustada apropiadamente en todas las tablas de índices relacionadas. Por eso que debes evitar crear un gran número de índices en las tablas muy modificadas y crear el número mínimo posible de índices, con el menor número posible de columnas en cada índice. Puedes solucionar este problema al escribir consultas que añadan o modifiquen filas en lotes, en vez de escribir una sola consulta por cada operación de insertar o modificar. Para cargas de trabajo de Procesamiento Analítico Online (OLAP), en las cuales las tablas tienen bajos requerimientos de modificación, puedes crear un gran número de índices que mejoren el rendimiento de las operaciones de recuperación de información.
Tamaño de la tabla
No es recomendable crear índices en tablas pequeñas, ya que lleva al Motor de SQL Server menos tiempo de escanear las tablas subyacentes que atravesar el índice al buscar por una información específica. En este caso, el índice no será usado y todavía afectará el rendimiento de la modificación de la información, como también siempre será ajustado cuando se modifique la información de la tabla subyacente.
Columnas de la tabla
Además de las características de carga de trabajo de la base de datos, las características de las columnas de la tabla que son usadas en las consultas presentadas deberían también ser consideradas al diseñar un índice. Por ejemplo las columnas con los tipos de información numérica exacta, como información de tipo INT y BIGINT y que son usadas como UNIQUE y NOT NULL son consideradas columnas óptimas para participar en la clave de índice.
En la mayoría de los casos, una larga consulta es causada por poner índice a una columna con pocos valores singulares. A pesar de que no es posible de añadir las columnas con tipos de datos ntext, text, image, varchar(max), nvarchar(max), y varnibinary(max) a las columnas de clave de índice, es posible añadir estos tipos de información a columnas de índice no-clave, pero solo en el caso de necesidad crítica. Una columna con tipo de información XML puede ser añadida solo a un tipo de índice XML.
Orden y Clasificación de columnas
Es recomendable crear los índices en columnas que son usadas en consultas y unir condiciones en el orden correcto que es especificado en el postulado. De este modo, el objetivo es guardar la clave de índice corta, sin incluir las columnas raramente usadas, para minimizar la complejidad del índice, almacenar y mantener los gastos. Puedes también mejorar el rendimiento de la consulta al crear una cobertura de índice que contiene toda la información requerida para la consulta, sin la necesidad de leer de la tabla subyacente.
Para ver la importancia del orden de columna en la clave de índice, déjanos crear una tabla simple de prueba usando la declaración CREATE TABLE T-SQL de abajo:

Y crear un índice no agrupado en esta tabla usando las columnas LastName y FirstName como se muestra abajo:

Then we will fill the table with 10K records, using the ApexSQL Generate, test data generator tool, as shown below:

La tabla está lista ahora para nuestro escenario de prueba. Ejecutaremos dos consultas SELECT, la primera buscará usando la columna FirstName, que es la segunda columna en las columnas de clave de índice, y la segunda consulta buscará usando la columna LastName, que es la primera columna en las columnas de clave de índice.
De éste resultado, es claro que el Motor de SQL Server va a escanear toda la información de índice para buscar los estudiantes con el valor FirstName especificado en la cláusula WHERE. El Motor SQL Server no puede tomar plenamente beneficios de los índices creados, debido al orden de las columnas en el índice creado. En la segunda consulta, el Motor de SQL Server busca directamente los valores requeridos y toma beneficios del índice creado mientras usamos la columna LastName en la cláusula WHERE, la cual es la primera columna en el índice. Puedes ver también que el peso de la consulta que está escaneando el índice es 92 % del peso total, comparada a la que está escaneando el índice con peso igual a 8 % del peso total, como es mostrado claramente abajo:

Es también recomendable al diseñar un índice, considerar si las columnas que participan en la clave de índice serán clasificadas por orden ascendente o descendente, con el orden ascendente como el orden por defecto, dependiendo del requerimiento del sistema. En la tabla de Estudiante previamente creada, asume que estamos interesados en obtener la información de estudiantes clasificada ascendiendo por el FirstName y descendiendo por el LastName. Si la tabla no tiene índice creado en el FirstName y LastName, después de dejar el antiguo índice como es mostrado abajo:

Después ejecutar la consulta de abajo, que obtendrá el resultado clasificado ascendiendo por el FirstName y descenciendo por el LastName. Verás que un operador extra será usado en el plan de ejecución para Clasificar el resultado como especificado en la cláusula ORDER BY. Puedes imaginar el tiempo de ejecución extra consumido y el costo de rendimiento que es causado por el operador Clasificar, como se muestra abajo:

Si creamos un índice en esa tabla que incluye ambos FirstName clasificado ascendiendo y LastName, clasificiado descendiente, usando la declaración CREATE INDEX T-SQL de abajo:

Cuando tratas de correr la misma consulta previa otra vez, verás que el Motor de SQL Server va a directamente buscar la información requerida, sin un costo extra de clasificar la información, como si ya correspondiera el orden especificado en la cláusula ORDER BY, como se muestra abajo:

Tipo de Índices
Estudiar los tipos de índices de SQL Server disponibles es también recomendable, para decidir qué tipo de índice va a mejorar el rendimiento de la actual carga de trabajo, como los Índices Agrupados que pueden ser usados para clasificar grandes tablas, Índices de Almacenaje de columnas que pueden ser usados para mejorar el rendimiento de la carga de trabajo sólo lectura del procesamiento del Procesador Analítico Online (OLAP) de la información de los almacenes de base de datos o Índices Filtrados para columnas que tienen subgrupos bien definidos de información, como los valores NULL, distintos rangos o valores categorizados.
Almacenamiento de Índice
La localización de almacenaje del índice también puede afectar en el rendimiento de las consultas leyendo del índice. Por defecto, el índice será almacenado en el mismo grupo de archivo como la tabla subyacente en la cual el índice es creado. Si diseñas un índice No Agrupado para ser almacenado en un archivo de información diferente del archivo de información de la tabla subyacente y localizado en una unidad de disco separado, o horizontalmente separar el índice para separar múltiples archivos de grupo, el rendimiento de las consultas que se están leyendo del índice serán mejoradas, debido al mejoramiento del rendimiento I/O obtenido al pulsar en diferentes archivos de información y unidades de disco al mismo tiempo.
El almacenamiento inicial del índice puede ser también optimizado al configurar la opción FILLFACTOR (Factor de relleno), para un valor diferente al del valor por defecto de 0 a 100. FILLFACTOR es el valor que determina el porcentaje de espacio en cada página de nivel-hoja para ser llenada con información. Configurando el FILLFACTOR a 90 % cuando creas o reconstruyes un índice, el SQL Server tratará de dejar 10 % de cada página hoja vacía, reservando el restante de cada página como espacio libre para el crecimiento futuro para prevenir la separación de la página y los problemas de rendimiento de fragmentación del índice.
Conclusión
Después de dibujar tu estrategia de diseño de índices, puedes fácilmente empezar a aplicarla para crear nuevos índices útiles que el Optimizador de Consultas de SQL Server escogerá y confiará, para crear el plan de ejecución más óptimo para las consultas presentadas, proveyendo el mejor rendimiento general del sistema. Sigue sintonizado para los siguientes artículos en estas series, para familiarizar con las operaciones que pueden ser realizadas en los índices y como diseñar, crear, mantener y sintonizar índices.
Tabla de contenido
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.



He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019