

En los artículos previos de estas series (véase al fondo para el índice completo), describimos en detalle la estructura de las tablas e índices de SQL Server, lo básico y las líneas guía que nos ayudan a diseñar un índice apropiado y finalmente la lista de operaciones que pueden ser realizadas en los índices SQL Server. En este artículo, veremos cómo podríamos diseñar un índice agrupado efectivo del cual el Optimizador de Consultas SQL Server podrá siempre sacar beneficios, al hacer más rápido el proceso de recuperación de datos, la cual es la principal meta de construir un índice.
Resumen de la estructura de Índice Agrupado
En una tabla Agrupada, un índice agrupado SQL Server es usado para almacenar las filas de información clasificadas basados en los valores clave de índice agrupado. SQL Server nos permite crear solo un índice Agrupado por cada tabla, ya que la información puede ser clasificada en la tabla usando un criterio de orden. En las tablas montón, la ausencia de los índices agrupados significa que la información no es clasificada en la tabla subyacente.
El índice agrupado es organizado como páginas de 8 KB usando estructuras B-Árbol, para activar el Motor SQL Server para encontrar las filas requeridas asociadas con los valores de índice claves rápidamente. Cada página en la estructura de índice B-Árbol es considerada como un modo de índice. El nodo de nivel superior es llamado el nodo Raíz y los nodos de nivel inferior son llamados nodos Hoja, donde las páginas de tablas de información son almacenadas y clasificadas basadas en los valores de índice clave. Todos los nodos que están localizados entre los nodos de niveles raíz e hoja son llamados nodos de nivel Intermedio. Todas las páginas localizadas en los niveles raíz e intermedio contienen los valores de índice clave clasificados con un puntero al siguiente nodo de nivel intermedio o la página de información en el índice de nivel hoja. Además de clasificar la información de las páginas de índice basados en los valores de índice clave, las páginas mismas serán clasificadas y unidas en una lista doblemente unida con el índice. Cualquier valor nuevo insertado en ese índice seguirá el orden de secuencia del índice clave entre las filas existentes.
Un índice agrupado SQL Server contiene uno o más unidades de distribución que son usados para almacenar y administrar la información almacenada dependiendo del tipo de información de las columnas clava en ese índice, con la unidad de distribución IN_ROW_DATA disponible en todos los índices agrupados. La unidad de distribución LOB_DATA será utilizada en el índice agrupado que tiene un objeto de información grande (LOB) y las unidades de distribución ROW_OVERFLOW_DATA para las columnas de extensión variable que exceda el tamaño límite de la fila de 8.060 bytes. La figura que se muestra abajo de Microsoft Books Online resume la estructura descrita del índice en una sola partición, que siempre tendrá un valor index_id igual a 1 in la tabla de sys.partition.

Consideraciones de diseño de índices agrupados
El índice agrupado puede ser beneficioso para las consultas que leen grupos grandes de resultados de información de orden secuencial. En este caso el Motor de SQL Server localizara la fila con el primer valor requerido usando el índice agrupado, y continua secuencialmente para recuperar el resto de las filas que están físicamente adyacentes en las páginas de índice con el orden correcto, sin consumir el tiempo del Motor de SQL Server y los recursos en clasificar la información que ya está clasificada en el índice agrupado, afectando el rendimiento de las consultas positivamente en general. Por ejemplo, si la consulta retorna todas las filas con el valor ID mayor que 950, el Motor de SQL Server usara el índice agrupado para localizar la fila con el valor ID igual a 950 y continuara recuperando el resto de las filas secuencialmente.
Las características de las mejores claves agrupadas pueden ser resumidas en pocos puntos que son seguidos por la mayoría de los diseñadores:
- Corto: A pesar que el SQL Server nos permite añadir hasta 16 columnas a los índices agrupados clave, con un máximo tamaño clave de 900 bytes, el típico índice agrupado clave es mucho más pequeño de lo que es permitido con la menor cantidad de columnas posible. El índice clave agrupado amplio también afectara todos los índices no agrupados construidos sobre ese índice agrupado como el índice clave agrupado será utilizado como clave de búsqueda para todos los índices no agrupados apuntando a él.
- Estático: Es recomendado escoger las columnas que no son cambiadas frecuentemente en el índice agrupado clave. Cambiar los valores de los índices agrupados clave en el orden correcto.
- Incremental: Usando una columna incremental, como la columna IDENTITY, como un índice agrupado clave ayudara a mejorar el proceso INSERT, que va a directamente insertar los valores nuevos en el final lógico de la tabla. Esta es una decisión muy recomendada ayudara a reducir la cantidad de memoria requerida para las memorias intermedias de la página, minimizar la necesidad de dividir la página en dos páginas para hacer entrar los valores nuevos insertados y la ocurrencia de fragmentación que requiere construir o reorganizar el índice de nuevo.
- Único: Es recomendado para declarar la columna de índice agrupado clave o combinación de columnas como única para mejorar el rendimiento de consultas. De otro modo el SQL Server va a automáticamente añadir una columna unificadora para aplicar la singularidad el índice agrupado clave.
- Accesible frecuentemente: Esto es debido al hecho de que las filas serán almacenadas en los índices agrupados en un orden clasificado basado en ese índice clave, que es usado para acceder a la información.
- Usado en la cláusula ORDER BY: En este caso, no es necesario que el Motor SQL Server clasifica la información para poder mostrarla, ya que las filas están ya clasificadas basadas en el índice clave usado en la cláusula ORDER BY.
Tipos de información apropiadas de Índices agrupados
Cuando se diseña un índice agrupado, deberías considerar que algunos tipos de información son mejores que otros tipos de información para ser usadas como claves agrupadas. Por ejemplo las columnas con tipos de información SMALLINT, INT y BIGINT son las mejores opciones como índices clave agrupados, especialmente cuando son usados en conjunción con la restricción IDENTITY, que aplica sus valores para incrementar secuencialmente. Además, los valores enteros de IDENTITY son estrechos, debido a su tamaño reducido, si aplicas la singularidad de la columna con una restricción y estática, como son generadas automáticamente por el sistema y no visibles a los usuarios.
A pesar de los valores GUIDs, que están almacenados en las columnas uniqueidentifier, están usualmente usadas como índices agrupados clave, hay algunos desafíos que acompañan ese diseño. El mayor desafío que afecta el rendimiento de clasificación del índice agrupado clave es la naturaleza del valor GUID que es mayor que los tipos de información entera, con tamaño de 16 bytes y que son generados de manera aleatoria, diferentemente de los valores enteros de IDENTITY que están incrementando continuamente. El gran tamaño y la generación aleatoria de los valores GUID siempre llevaran a la división de la página y problemas de fragmentación de índice, que afectara negativamente el rendimiento del uso de los índices agrupados.
Los tipos de información Character pueden ser también usados, pero no es recomendado como índices agrupados clave. Esto es debido al rendimiento de clasificación limitado de los tipos de información carácter, el gran tamaño, valores no incrementales, valores no estáticos que a menudo tienden a cambiar en las aplicaciones de negocio y no comparar como valores binarios durante el proceso de clasificación, como los mecanismos de comparación de caracteres dependen de la colación usada. Aunque los tipos de información Date no son únicos, tiene un tamaño pequeño y provee buen rendimiento de clasificación, especialmente para las consultas que buscan rangos de información.
Implementación de Índices Agrupados
Cuando tu creas una restricción PRIMARY KEY en una tabla, un índice agrupado único será creado automáticamente en la columna o columnas que participan en esa restricción para aplicar la restricción PRIMAREY KEY, dado el mismo nombre que el nombre de la restricción, a menos de que hayas definido un índice agrupado en la misma tabla. El SQL Server te permite especificar el tipo de índice que será creado automáticamente cuando creas una restricción UNIQUE para ser un índice agrupado, si no hay un índice agrupado creado en esta tabla, debido al hecho de que, solo un índice agrupado puede ser creado por cada tabla. Puedes también crear el índice agrupado independientemente de las restricciones si un índice no agrupado es usado para aplicar la restricción PRIMARY KEY.
Un índice agrupado puede ser creado usando el SQL Server Management Studio o usar el comando CREATE CLUSTERED INDEX T-SQL. Para poder crear el índice agrupado, el usuario debe ser un miembro de los roles de base de datos fijos db_owner o db_ddladmin o miembro del rol del server fijo de sysadmin.
Déjanos crear una nueva tabla para ser usada en nuestra demo, en la cual el limite PRIMARY KEY usara un índice no agrupado para aplicarlo, usando la declaración CREATE TABLE T-SQL de abajo:
|
1 2 3 4 5 6 7 8 9 10 11 |
USE SQLShackDemo GO CREATE TABLE ClusteredIndexDemo ( ID INT IDENTITY (1,1) NOT NULL, GUID uniqueidentifier NOT NULL, EmployeeName NVARCHAR(200) NOT NULL, BirthDate DATETIME NOT NULL, EmployeeAddress NVARCHAR(MAX), CONSTRAINT PK_ClusteredIndexDemo_GUID PRIMARY KEY NONCLUSTERED (GUID) ) |
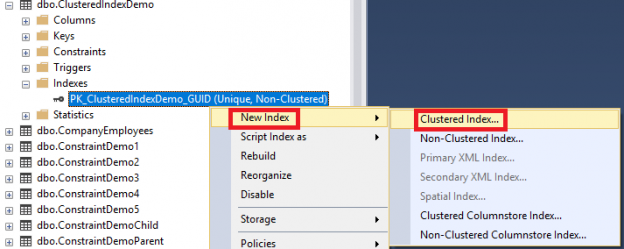
Teniendo un índice no agrupado definido en la tabla previa, podemos crear un índice agrupado usando el SQL Server Management Studio al navegar la tabla en la cual necesitamos crear el índice agrupado, después se debe hacer unclic derecho en los nodos Índices debajo esa tabla y desde la opción Nuevo Índice escoge el tipo de índice agrupado, como se muestra abajo:

Del cuadro de dialogo New Index mostrado, el nombre de la tabla sobre la cual en índice será creado y el tipo de índice será llenado automáticamente. Necesitas proveer el nombre del índice, siguiendo de la convención de nombre de tu compañía, la singularidad de esos valores de índice clave y desde el botón Add, puedes escoger la columna o lista de columnas que van a participar en ese índice clave, como se muestra abajo:

Puedes realizar la misma tarea desde la Tabla Designer, al hacer clic derecho en la tabla sobre la cual el índice será creado y escoger la opción Design como se muestra abajo:

En la ventana Tabla Designer mostrada, apretar clic derecho en el espacio vacío y escoge la opción Índices/Claves mostrada abajo:

De la ventana de dialogo que aparece, apretar clic en el botón Add para añadir un nuevo índice agrupado, al configurar Create As Clustered to Yes, Specify the index name, la singularidad del índice agrupado y la lista de columnas, con el orden de clasificación apropiado, que será incluido en el índice clave agrupado, como se muestra abajo:

Los índices agrupados pueden también ser creados usando el comando T-SQL CREATE CLUSTERED INDEX al especificar el nombre del índice, el nombre de la tabla sobre el cual el índice será creado, la singularidad de los valores del índice agrupado clave y la lista de columnas que serán incluidas en el índice agrupado clave, como se muestra abajo:
|
1 2 3 4 5 |
CREATE UNIQUE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( ID ASC ) WITH( SORT_IN_TEMPDB = ON, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
Considera tomar beneficios de la lista de opciones de la creación de índice especificado en la declaración previa CREATE INDEX, especialmente cuando creas un índice agrupado en tablas largas, para mejorar el rendimiento del proceso de creación de índice.
Comparación de rendimiento
Para proceder con el demo, déjanos llenar la tabla creada con 100 mil registros, usando ApexSQL Generate, como se muestra abajo:

Hasta este punto, la tabla es llenada y clasificada basada en el ID de la columna. Si ejecutamos la consulta de abajo SELECT que busca basada en la columna ID y verifica la estadística TIME y IO generada por ejecutar la consulta:
|
1 2 3 4 5 |
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM [dbo].[ClusteredIndexDemo] WHERE ID>1000 and [EmployeeAddress] LIKE '%Hillcrest%' |
La estadística generada mostrara que 1075 operaciones lógicas leídas son realizadas para recuperar la información requerida, 203 ms consumidos del tiempo de CPU y 255 ms tomados para ejecutar la consulta, como se muestra abajo:

Abandonamos el índice agrupado y creamos uno nuevo usando la columna GUID:
|
1 2 3 4 5 6 7 |
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo GO CREATE UNIQUE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( GUID ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
Y ejecutamos la declaración de abajo SELECT que busca basado en los valores de la columna GUID:
|
1 2 |
SELECT * FROM [dbo].[ClusteredIndexDemo] WHERE GUID <> 'CB2F45A0-185F-9884-88EB-B7C497AB61EA' and [EmployeeAddress] LIKE '%Hillcrest%' |
Las estadísticas generadas Time y IO mostraran que 1196 operaciones lógicas leídas son realizadas para recuperar la información requerida basado en los valores de la columna GUID, 2018 ms consumidos del tiempo del CPU y 276 ms tomados para ejecutar la consulta. Todos los contadores muestran que usando la columna GUID como índice agrupado clave es peor que usar la columna ID, como se muestra abajo:

|
1 2 3 4 5 6 7 |
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo GO CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( EmployeeName ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
Luego ejecuta la declaración de abajo SELECT que busca basado en los valores de la columna EmployeeName:
|
1 2 |
SELECT * FROM [dbo].[ClusteredIndexDemo] WHERE [EmployeeName] <> 'Gianna' and [EmployeeAddress] LIKE '%Hillcrest%' |
Veras de la estadística generada Time y IO que, 1287 operaciones lógicas leídas son realizadas para recuperar la información requerida basada en los valores EmployeeName, 2018 ms consumidos del tiempo de CPU y 289 ms tomados para ejecutar la consulta. Todos los contadores otra vez indican que usar la columna carácter EmployeeName como índice agrupado clave es peor que usar las columnas ID y GUID, como se muestra abajo:

Si abandonamos el índice agrupado y creamos uno nuevo usando la columna BirthDate datetime:
|
1 2 3 4 5 6 7 |
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo GO CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( BirthDate ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
Y ejecutamos la declaración de abajo SELECT que busca basada en los valores de la columna BirthDate:
|
1 2 |
SELECT * FROM [dbo].[ClusteredIndexDemo] WHERE BirthDate BETWEEN '1950-01-01' AND '1950-12-31' AND [EmployeeAddress] like '%Hillcrest%' |
Las estadísticas Time y IO generadas después de ejecutar la consulta mostraran que solo 7 operaciones lógicas leídas son realizadas para recuperar la información requerida basado en el rango de valores de BirthDate, 0ms consumidos del tiempo de CPU y 47 ms tomados para ejecutar la consulta. Es claro por el resultado que, usando la columna BirthDate Datetime como índice agrupado clave es la mejor opción cuando se busca basado en un rango de fecha, como se muestra abajo:

Finalmente, si tratas de abandonar el índice agrupado y creas uno nuevo usando la columna carácter EmployeeAddress:
|
1 2 3 4 5 6 7 |
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo GO CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( EmployeeAddress ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
La declaración CREATE INDEX fallará , mostrando que el tipo de información NVARCHAR(MAX) no es permitida como un índice agrupado clave, como se muestra en el mensaje de error de abajo:

Como puedes ver de los resultados previos, un índice agrupado que es diseñado apropiadamente puede reducir la cantidad de consumo de recursos del CPU, por lo tanto mejorar las consultas y el rendimiento del sistema en general. El Optimizador de Consultas de SQL Server decide usar el índice agrupado para recuperar la información requerida, como sea más eficiente, más rápido y con menos consumo de recursos que escaneando la tabla entera, además de tener la información clasificada en las páginas de índice.
Ten en consideración que, cuando creas un índice agrupado en la tabla, todos los índices no agrupados creados en la tabla de montón serán reconstruidos para remplazar el identificador de fila (RID) con la clave de índice agrupado. De manera que, es siempre mejor empezar creando el índice agrupado y luego proceder creando el índice no agrupado sobre él.
En este artículo, tratamos de cubrir todos los aspectos del diseño del índice agrupado. En el siguiente artículo de estas series, vamos a discutir sobre como diseñar un índice No Agrupado óptimo y efectivo. ¡Sigue sintonizado!Tabla de contenido
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.



He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019