

En mi artículo previo, Resumen de la estructura de la tabla de SQL Server, describimos en detalle la diferencia entre estructuras de tabla de Montón, en las cuales las páginas de información no están clasificadas en ningún criterio de orden y las páginas mismas no están clasificadas o unidas la una con la otra, y las tablas Agrupadas, en las cuales la información está clasificada dentro de las páginas de información y las páginas serán también unidas en una doble lista unida, basada en la clave de índice. En este artículo, iremos a través de la estructura del Índice de SQL Server mismo.
El índice de SQL Server es considerado como uno de los más importantes factores del rendimiento del proceso de sintonía, que es creado para acelerar la recuperación de información y el procesamiento de las operaciones de consulta de la tabla o vista de base de datos, al proveer rápido acceso a las filas de la tabla de base de datos, sin la necesidad de escanear toda la información de la tabla, para recuperar la información requerida. Puedes imaginar la tabla índice como un índice de libro que te permite encontrar la información requerida muy rápido dentro de tu libro, en vez de leer todas las páginas de tu libro para encontrar un tema específico. Un ejemplo del índice de un libro que localiza la página donde puedes encontrar cada palabra es mostrado abajo:

Asume que tienes una consulta que recupera la lista de información de los empleados de la tabla de Empleados basada en la columna EmployeeID. Sin tener un índice en la columna EmployeeID, el SQL Server escaneará todas las filas de la tabla para recuperar la información requerida. Si creas un índice en la columna de EmployeeID en la tabla de Empleados, y realizas una búsqueda basada en el valor EmployeeID, el motor de SQL Server buscará los valores de EmployeeID requeridos en el índice y usará ese índice para localizar el resto de la información de los empleados de las filas relacionadas en la tabla fuente, proporcionando un mejoramiento del rendimiento y reduciendo el esfuerzo requerido para localizar la información requerida, como se muestra en la figura abajo:

La capacidad de una rápida búsqueda proporcionada por el índice es alcanzada debido al hecho de que el índice SQL Server es creado usando la forma estructural de B-Árbol, que hizo páginas de 8K, cada página en esa estructura es llamada un nodo de índice. La estructura de B-Árbol proporciona al Motor SQL Server un más rápido modo de mover a través de las filas de la tabla basado en la clave de índice, que decide navegar a la izquierda o derecha, para recuperar los valores requeridos directamente, sin tener que escanear todas las filas subyacentes de la tabla. Puedes imaginar la degradación del rendimiento que puede ocurrir debido a un gran escaneo en la base de datos de la tabla.
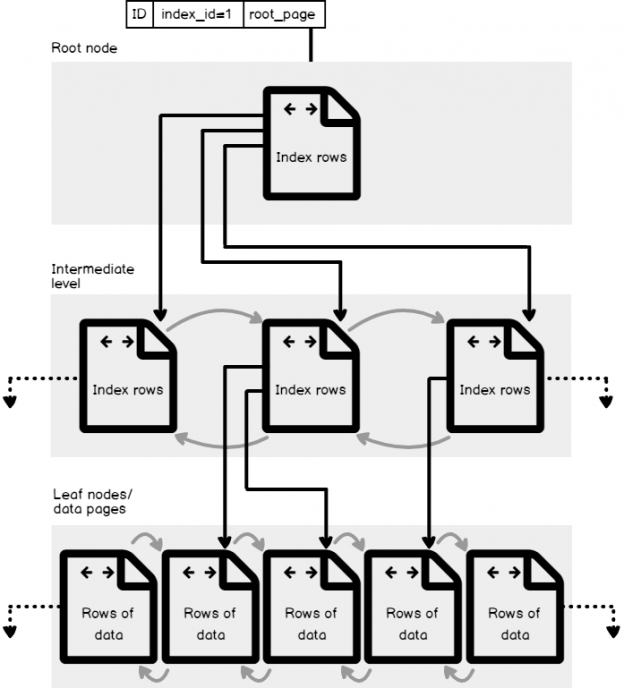
Es claro en la figura inferior de Estructura de índice en árbol B, que la estructura de B-Árbol del índice consiste en tres niveles principales: El Nivel Raíz, el nodo más alto que contiene una sola página índice, forma cual SQL Server comienza su búsqueda de información, el Nivel Hoja, el nivel más bajo de los nodos que contiene páginas de información que estamos buscando, con los números de páginas hoja depende de la cantidad de información almacenada en el índice, y finalmente el Nivel Intermedio, uno o múltiples niveles entre el nivel raíz y el hoja que contiene los valores de clave de índice y los punteros a las siguientes páginas de nivel intermedio o las páginas de información hoja. El número de niveles intermedios depende de la cantidad de información almacenada en el índice.

Asume que creamos un índice en una de nuestras tablas de base de datos en la columna ID. Cuando corres una búsqueda de consulta en filas específicas de esa tabla, basado en valores ID de estas filas, el Motor SQL Server empezara navegando desde los nodos raíz, para determinar cuál página referenciar en el nivel alto intermedio, y luego continuar hacia abajo a través los nodos intermedios para identificar la dirección del siguiente nodo intermedio, hasta que alcanza la hoja meta que contiene la fila de información requerida o el puntero a esa fila en la tabla principal, dependiendo del tipo de índice.
Por ejemplo, si tienes un problema de consulta que busca la fila con el valor ID igual a 57. El Motor SQL Server empezara a buscar el nodo raíz del índice, donde encontrará que el valor ID de 57 existe en el segundo nodo intermedio. En el segundo nodo intermedio, encontrará también que el valor ID de 57 está localizando en el nodo hoja número 6, donde el registro con el valor ID es igual a 57, o el puntero a esa fila será encontrado en el nodo hoja, como se muestra abajo:

Los índices de SQL Server pueden tener un gran número de nodos en cada nivel. Esto ayuda a mejorar la eficiencia de los índices creados al evitar la necesidad de profundidad excesiva en el índice. La profundidad de índice es el número de niveles desde la raíz del nodo de índice hasta los nodos hoja. Un índice que es relativamente profundo sufrirá problemas de degradación de rendimiento. En cambio, un índice con un gran número de nodos en cada nivel puede producir una estructura de índice muy plana. Un índice con solo 3 a 4 niveles es muy común.
Además de la profundidad del índice, hay otros dos importantes índices de medida que controla la efectividad del índice. La primera propiedad es la densidad de índice que es una medida de falta de singularidad de la información en una tabla. Una columna densa es la que tiene un alto número de duplicados. La segunda propiedad es la selectividad de índice, que es una medida de las filas escaneadas comparadas al número total de filas.
El SQL Server nos proporciona dos principales tipos de índices, el índice Agrupado que almacenan las filas de información de tabla presentes en el nivel hoja de índice, además de controlar el criterio de clasificación de la información dentro de las páginas de información y el orden de las páginas mismas, basado en la clave de índice agrupado. Esta es la razón detrás la habilidad de crear solamente un índice agrupado en cada tabla. El índice No agrupado contiene solo los valores de las columnas de clave del índice con un puntero en las filas presentes de información almacenadas en el índice agrupado en la tabla subyacente, sin controlar el orden de la información dentro de las páginas y el orden de las páginas índices. SQL Server te permite crear hasta 999 índices no agrupados en cada tabla. Recordamos del anterior artículo que la tabla con índice no agrupado es llamada tabla Montón, sin criterio de controla de la información y el orden de las páginas, y la tabla que es clasificada usando un índice agrupado es llamada tabla Agrupada. Un índice agrupado será creado automáticamente cuando definas un límite de Clave Primaria en la tabla, si no hay índices agrupados predefinidos en la tabla.
Hay otros tipos de índices de SQL Server, como el índice Único que aplica la singularidad de los valores de las columnas, creados automáticamente cuando se define un límite único, el índice Compuesto que contiene más de una columna clave y el índice Cubierta que contiene todas las columnas requeridas para una consulta específica. Iremos a través de todos estos tipos en detalle en los siguientes artículos de ésta serie.
En este punto, ya deberías tener un gran entendimiento sobre la estructura de la tabla, la estructura del índice y los beneficios generales de añadir índices. Antes de ir a través del diseño del índice, uso y mejoramiento, debes tomar en consideración que el índice es una espada de doble filo, donde un índice bien diseñado mejorará el rendimiento de tu sistema y acelerará el procesamiento de recuperación de información. Por otro lado, un índice mal diseñado causará una degradación del rendimiento en tu sistema y te costara espacio extra en tu disco y retraso en la inserción de información y operaciones de modificación. Es mejor siempre probar el rendimiento del sistema antes y después añadir el índice en el ambiente de desarrollo, antes de añadirlo al ambiente de producción.
Tabla de contenido
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.



He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019