

En los artículos previos de estas series, hemos descrito la estructura de las tablas e índices de SQL Server, los conceptos principales que son usados para describir el índice, lo básico y las líneas guía que son usadas para diseñar el índice apropiado. En este artículo, iremos a través de las operaciones que pueden ser realizadas en los índices de SQL Server.
Creando Índices
Antes de crear un índice, es mejor seguir las líneas guía de diseño del índice y mejores prácticas que son descritas en el artículo previo, para determinar las columnas que van a participar en el índice, el tipo de índice creado, las opciones de índice apropiadas, como el FillFactor, o Sort en TempDB y la localización de almacenaje de ese índice.
El índice SQL Server puede ser creado usando la declaración CREATE INDEX T-SQL o de la caja de diálogo New Index usando la herramienta de SQL Server Management Studio, al proveer:
- El nombre del índice,
- El tipo de índice,
- La singularidad de los valores índice clave,
- El nombre de la tabla en el cual el índice será creado,
- La lista de columnas que participarán en ese índice
- Y diferentes opciones de índice como el FillFactor, Sort en TempDB, dejando los índices similares
- Y los grupos de archivos de índice y localización
La sintaxis CREATE INDEX T-SQL de abajo es usada como una plantilla para crear un nuevo índice SQL Server. La ausencia de la opción UNIQUE no forzará la singularidad de los valores de la clave índice. En un índice singular, ningunas dos filas están permitidas de tener el mismo valor de clave de índice. Si el tipo de índice no es especificado en la declaración CREATE INDEX T-SQL, un índice No Agrupado será creado.
|
1 2 3 4 5 6 7 |
CREATE [UNIQUE] [ CLUSTERED | NONCLUSTERED ] INDEX [index_name] ON [TableName] ( [Column1] ASC, [Column2] ASC ) ON PRIMARY WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO |
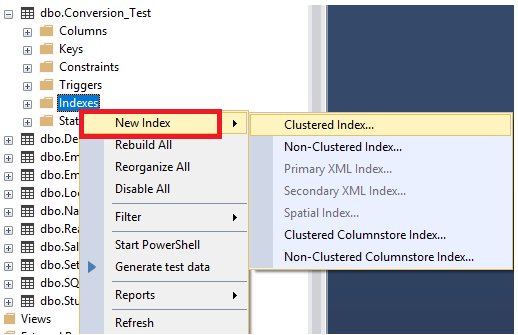
La misma operación puede ser realizada usando el SQL Server Management Studio, al navegar en la tabla donde necesitas crear un índice, clic derecho en los nodos de índices y escoge la opción New Index, de la cual puedes especificar el tipo de índice a ser creado como se muestra abajo:

El nombre de la tabla será llenado automáticamente de la pestaña General del cuadro de diálogo de New Index mostrado, con un nombre sugerido editable del índice. El tipo de índice será también llenado automáticamente de la lista de tipos provista, con la posibilidad de especificar la singularidad de ese índice y la lista de columnas que serán añadidas a esa lista y el orden de cada columna, como se muestra claramente abajo:

En la tabla de Opciones del cuadro de diálogo de New Index, puedes cambiar los valores por defecto de las diferentes opciones de creación de índice, igual que las especificadas en la cláusula WITH de la declaración CREATE INDEX T-SQL, como se muestra abajo:

La localización de la configuración del almacenaje del índice, como el grupo de archivo y el esquema de partición en los cuales el índice será almacenado, puede ser especificada en la pestaña Storage del cuadro de diálogo New Index, como se muestra abajo:

De la pestaña Filter del cuadro de diálogo New Index, puedes especificar la condición WHERE del índice filtrado, para seleccionar la información para ser almacenada en un índice filtrado creado, como se muestra abajo:

Los índices SQL Server pueden ser creados indirectamente al definir las restricciones PRIMARY KEY y UNIQUE dentro de las declaraciones CREATE TABLE o ALTER TABLE. SQL Server creará un índice agrupado único para aplicar la restricción PRIMARY KEY a menos que definas un índice agrupado en esa tabla. Recuerda que no podemos crear más de un índice agrupado por cada tabla. Un índice único no agrupado será creado automáticamente para aplicar la restricción UNIQUE. Deberías obtener permisos de la tabla CONTROL o ALTER para poder crear un índice.
Asume que planeamos crear la tabla de abajo que contiene dos columnas, la columna de ID como PRIMARY KEY y la columna STD Name como UNIQUE, usando la declaración CREATE Table T-SQL de abajo:
|
1 2 3 4 5 6 |
USE SQLShackDemo GO CREATE TABLE IndexDemo ( ID INT IDENTITY (1,1) PRIMARY KEY, STD_Name NVARCHAR(50) NOT NULL UNIQUE ) |
Viendo la tabla creada del explorador objeto del SQL Server Management Studio, verás que dos nuevos índices serán creados en esa tabla automáticamente, sin proveer ninguna declaración CREATE INDEX. Un índice agrupado será creado para aplicar la restricción PRIMARY KEY y un índice único No Agrupado será creado para aplicar la restricción UNIQUE, como se muestra abajo:

Crear nuevos índices en largas tablas debería ser planeado cuidadosamente, debido al impacto de rendimiento de este proceso en un ambiente de producción. Necesitas planificar cuidadosamente empezando de la creación de índices agrupados, después de que puedas crear los índices No Agrupados sobre ellos.
También, ajustando la opción ONLINE a ON cuando creas el índice, habilitará la recuperación de otra información o procesos de modificación en la tabla subyacente para continuar prevenir el proceso de creación de índices de fijar la tabla. Por otro lado, el proceso de creación de índice ONLINE tomará más largo tiempo que el proceso de creación por defecto offline.
Usando la opción SORT_IN_TEMPDB puede ayudar a reducir el tiempo requerido para crear el índice, tomando en consideración que el tempdb es recibido en una unidad de disco separada que la base de datos del usuario.
SQL Server nos ayuda a crear hasta un índice agrupado, 999 índices no agrupados, 249 índices XML, 249 índices Espaciales en cada tabla. Puedes añadir hasta 16 columnas clave por índice, con tamaño máximo permitido para un registro de índice clave igual a 900 bytes. No es permitido añadir columnas con tipos de información image, ntext, text, varchar(max), nvarchar(max), varbinary(max), and xml al índice clave. El número, tamaño de registro y limitación de tipo de información de las columnas de índice clave pueden ser evadidas al incluir las columnas No-Clave en los índices, mientras vamos a ver en detalle en el artículo Diseño efectivo de índices no agrupados.
Deshabilitando Índices
Cuando desactivas el índice SQL Server, la definición, estadísticas, y la información de ese índice no será removidos del catálogo del sistema, pero no podrás acceder a ese índice. Desactivando el índice No agrupado te prevendrá de acceder solo a ese índice. Por otro lado desactivando el índice agrupado te prevendrá de acceder a la información de la tabla subyacente, hasta que dejes o reconstruyas el índice.
Puedes decidir de desactivar un índice temporalmente debido a muchas causas, como solucionar problemas de un escenario específico, corrigiendo un error de disco I/O antes de reconstruir el índice, o eliminando el espacio del disco temporario requerido para almacenar la antigua y nueva versión del índice durante el proceso de reconstrucción de índice, donde solo 20 por ciento del tamaño del índice será requerido para clasificar la información del índice
El Motor de SQL Server desactiva índices de base de datos que puedan contener una expresión, objetos de base datos o colaciones que puedan ser cambiadas o puedan tener conflicto con un cambio en el proceso de mejoramiento, automáticamente cuando se realiza un proceso de mejoramiento a una nueva edición de Service Pack para SQL Server, y reconstruye automáticamente una vez que el proceso de mejoramiento es completado exitosamente.
Un índice puede ser desactivado manualmente usando la declaración ALTER INDEX DISABLE T-SQL. En la tabla IndexDemo previamente creada, si planeamos desactivar el índice No-agrupado, que es usado para aplicar la singularidad de la columna STD Name, usando la declaración ALTER INDEX DISABLE T-SQL, y ver el plan de ejecución de la declaración simple SELECT antes y después de desactivar el índice:
|
1 2 3 4 5 6 |
SELECT * FROM IndexDemo WHERE STD_Name ='CC' GO ALTER INDEX [UQ__IndexDem__6F98476D087DAAD3] ON [IndexDemo] DISABLE GO SELECT * FROM IndexDemo WHERE STD_Name ='CC' GO |
Verás que el Motor SQL Server realiza una Búsqueda de Índice en el índice No-agrupado para obtener la información requerida en la primera consulta SELECT. Después de desactivar los índices No-agrupados, el índice ya no es accesible. Entonces el Motor SQL Server realiza un escaneo de índice en los índices agrupados, como se muestra claramente abajo:

Si tratamos de desactivar el índice agrupado esta vez, usando la declaración ALTER INDEX DISABLE T-SQL, después tratamos de correr la misma declaración SELECT en esa tabla:
|
1 2 3 4 |
ALTER INDEX [PK__IndexDem__3214EC27DF7B8FBD] ON [IndexDemo] DISABLE GO SELECT * FROM IndexDemo WHERE STD_Name ='CC' GO |
La consulta SELECT va a fallar, mostrando que la tabla ya no es accesible después de deshabilitar el índice agrupado en la tabla, como se muestra en el mensaje de error de abajo:

El índice desactivado puede ser activado otra vez al reconstruir el índice usando la declaración ALTER INDEX REBUILD T-SQL o creando el índice otra vez usando la declaración CREATE INDEX T-SQL con la opción DROP_EXISTING igual a ON. Si logramos activar el índice agrupado en la tabla demo otra vez usando la declaración ALTER INDEX REBUILD T-SQL de abajo, y luego tratar de correr la misma declaración SELECT:
|
1 2 3 4 |
ALTER INDEX [PK__IndexDem__3214EC27DF7B8FBD] ON [IndexDemo] REBUILD GO SELECT * FROM IndexDemo WHERE STD_Name ='CC' GO |
Verás que eres ahora capaz de acceder a esa tabla y recuperar la información requerida, como se muestra abajo:

También, activando el índice No-agrupado, usando la declaración CREATE INDEX WITH DROP_EXISTING T-SQL de abajo:
|
1 2 3 4 5 6 |
SELECT * FROM IndexDemo WHERE STD_Name ='CC' GO CREATE UNIQUE INDEX [UQ__IndexDem__6F98476D087DAAD3] ON [IndexDemo] (STD_Name) WITH (DROP_EXISTING =ON) GO SELECT * FROM IndexDemo WHERE STD_Name ='CC' GO |
Verás que el Motor de SQL Server buscará ese índice directamente después de activarlo, comparado al escanear el índice agrupado antes de activar el índice No agrupado, como se muestra abajo:

Renombrar Índices
Es mejor seguir una convención de nombramiento standard al crear los índices de SQL Server, para entender el propósito de ese índice desde el nombre del índice. Puedes especificar el tipo de índice, el nombre de la tabla en la cual el índice es creado y el nombre de las columnas que participan en ese índice, en el nombre del índice para hacerlo significante y único en el nivel de la tabla. Para los índices existentes, puedes remplazar el nombre actual del índice con un nuevo nombre que sigue la política convencional de nombramiento de tu compañía. Renombrar el índice no afectará la estructura del índice o la reconstruirá, solo cambiará el nombre de ese índice.
Por ejemplo cuando creas una restricción PRIMARY KEY o UNIQUE, el SQL Server creará un índice relacionado automáticamente para aplicar esa restricción, proveyendo un nombre largo que contiene el tipo de esa restricción, el nombre de la tabla y un valor único GUID como se muestra en el ejemplo previo.
El sistema de procedimiento de sp_rename puede ser usado para cambiar el nombre del índice, al proveer el antiguo nombre del índice y en nuevo nombre del índice. La declaración T-SQL de abajo es usada para cambiar el nombre del índice No-agrupado creado automáticamente para seguir nuestra convención de nombramiento:
|
1 |
EXEC sp_rename N'IndexDemo.UQ__IndexDem__6F98476D087DAAD3', N'UQ_IndexDemo_STD_Name', N'INDEX'; |
El nuevo nombre puede ser verificado de los nodos de índices de la tabla meta usando el SQL Server Management Studio, como se muestra abajo:

Abandonando Índices
Como describe el índice SQL Server, siempre recuerda que es una espada de doble filo que puede afectar negativamente el rendimiento del sistema en casos donde el índice está mal diseñado. Si se encuentra que un índice está mal diseñado, o que ya no es requerido, necesitarás abandonar ese índice de la tabla de base de datos y recuperar el espacio del disco consumido por el índice para ser usado por otros objetos de la base de datos. Dejando la tabla o vista también abandonará todos los índices creados en los objetos de la base de datos.
Abandonando el índice agrupado tomará tiempo extra y espacio temporal en el disco. Esto es debido al hecho de que toda la información almacenada en el nivel hoja del índice agrupado será almacenada en una tabla de montón no ordenada. Además, todos los índices No-agrupados serán reconstruidos para remplazar las claves de índice agrupado con punteros fila a la tabla montón. Puedes también realizar un abandono Online para el índice agrupado, con la habilidad de anular el valor por defecto de la base de datos MAXDOP por la actual consulta de abandono de índice agrupado solamente. En este caso, otras consultas de usuario que usen la tabla subyacente no serán bloqueadas por la operación DROP INDEX.
Un índice puede ser abandonado fácilmente usando la declaración DROP INDEX T-SQL, al proveer el nombre del índice y el nombre de la tabla donde el índice es creado como se muestra abajo:
|
1 |
DROP INDEX [UQ_IndexDemo_STD_Name] ON [dbo].[IndexDemo] |
Para índices creados manualmente, DROP INDEX será útil para abandonar el índice. Pero para los índices que son creados automáticamente para aplicar la restricción PRIMARY KEY y UNIQUE, no podrás quitarla a menos que abandones la restricción que creó el índice. Si tratas de correr la declaración previa DROP INDEX para quitar el índice creado para aplicar la restricción clave UNIQUE, la declaración fallará, mostrando que el índice es usado para la restricción UNIQUE KEY, como se muestra abajo:

Para abandonar el índice previo, deberíamos abandonar la restricción matriz, usando la declaración ALTER TABLE DROP CONSTRAINT T-SQL de abajo:
|
1 |
ALTER TABLE [dbo].[IndexDemo] DROP CONSTRAINT [UQ_IndexDemo_STD_Name] |
Que abandonará el índice automáticamente como se muestra abajo:

Configurando las opciones de Índice
Cuando creas o reconstruyes un índice, hay un número de opciones de índice a ser considerados y configurados. Estas opciones incluyen:
- PAD_INDEX: Usado para aplicar el porcentaje de espacio libre especificado por FillFactor al nivel intermedio páginas de índice durante la creación del índice.
- FILLFACTOR: Usado para configurar el porcentaje de espacio libre que el Motor de SQL Server dejará en el nivel hoja de cada página de índice durante la creación de índice. FillFactor debería ser un valor entero de 0 a 100 con 0 o 100 como valor por defecto, en la cual las páginas serán llenadas completamente durante la creación del índice.
- SORT_IN_TEMPDB: Especifica si la clasificación intermedia resulta, generada durante la creación del índice, será almacenada en tempdb.
- IGNORE_DUP_KEY: Especifica si un error de mensaje será mostrado cuando valores duplicados clave son insertados en un único índice.
- STATISTICS_NORECOMPUTE: Determina si la estadística de distribución del índice desactualizada será reprogramada automáticamente.
- DROP_EXISTING: Especifica que el índice existente nombrado será abandonado y recreado otra vez.
- ONLINE: Especifica si las tablas subyacentes son accesibles para consultas y modificación de información durante la operación de índice.
- ALLOW_ROW_LOCKS: Determina si los bloqueos de fila son permitidos a acceder en la información de índice.
- ALLOW_PAGE_LOCKS: Determina si los bloqueos de página son permitidos para acceder en la información de índice.
- MAXDOP: Usado para limitar el máximo número de procesadores usados en ejecución de plano paralelo de la operación de índice.
- DATA_COMPRESSION: Especifica el nivel de compresión de la información para los índices especificados, numero de partición, de rango de particiones, con valores NONE, ROW, y PAGE.
Puedes ver los valores actuales de estas opciones para un índice específico al consultar la vista de catálogo sys.indexes , usando la declaración SELECT de abajo:
|
1 2 3 4 |
SELECT * FROM sys.indexes WHERE name = N'PK__IndexDem__3214EC27DF7B8FBD'; GO |
Una captura de pantalla de los resultados obtenidos sería como:

La consulta CREATE INDEX de abajo es usada para crear un nuevo índice en una tabla demo, con un valor personalizado para la opción FillFactor, aplicando el valor FillFactor a las páginas de nivel intermedio como se muestra abajo:
|
1 2 3 |
CREATE INDEX IX_IndexDemo_STDName ON [dbo].[IndexDemo] (STD_Name) WITH (PAD_INDEX=ON, FILLFACTOR=90) |
La siguiente consulta ALTER INDEX es usada para reconstruir el índice, permitiendo el tipo de bloqueo de fila durante el proceso de reconstrucción de índice:
|
1 2 3 |
ALTER INDEX IX_IndexDemo_STDName ON [dbo].[IndexDemo] REBUILD WITH (ALLOW_ROW_LOCKS=ON) |
Puedes usar también la cláusula SET con la declaración ALTER INDEX para configurar las opciones ALLOW_PAGE_LOCKS, ALLOW_ROW_LOCKS, IGNORE_DUP_KEY y STATISTICS_NORECOMPUTE sin necesidad de reconstruir el índice, como la declaración de ALTER INDEX de abajo:
|
1 2 3 |
ALTER INDEX IX_IndexDemo_STDName ON [dbo].[IndexDemo] SET (ALLOW_PAGE_LOCKS=ON) |
Recuerda que la declaración ALTER INDEX T-SQL no puede ser usada para cambiar la estructura o columnas participantes del índice, solo te permite reconstruir (rebuild), reorganizar (reorganize), o CONFIGURAR (SET) las diferentes opciones del índice.
Hasta este punto, hemos mostrado profundamente la mayoría de las operaciones que pueden ser realizadas en los índices de SQL Server. En los siguientes artículos en estas series, vamos a describir cómo diseñar un útil y efecto índice agrupado. ¡Sigue sintonizado!
Tabla de contenido
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.



He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019