

En los artículos previos de estas series (véase el artículo entero TOC abajo), discutimos la estructura interna de las tablas SQL Server e índices, las principales líneas guía que puedes seguir para diseñar un índice apropiado, la lista de operaciones que pueden ser realizadas en los índice de SQL Server y finalmente cómo diseñar índices Agrupados y No agrupados efectivos del cual el Optimizador de Consultas SQL Server tomará siempre beneficios, al hacer más rápido el proceso de recuperación de información, el cual es la principal objetivo de crear un índice, en este artículo, necesitamos ir a través de diferentes tipos de índices SQL Server, arriba y abajo la clasificación de índices Agrupados y No agrupados, y cuando usarlos.
Índice Único
Un índice único es usado para mantener la integridad de la información de las columnas sobre las cuales es creado al asegurar que no hay valores duplicados en el índice clave, y la filas de la tabla, sobre la cual el índice es creado. Esto aseguro que la información será única basada en el índice clave, dependiendo de las características de la información que es almacenada en la columna del índice clave o la lista de columnas. Si el índice Único clave consiste en una columna, el SQL Server garantizará que cada valor en el índice clave es único. Por otro lado, el índice Único clave consiste en múltiples columnas, cada combinación de valores en ese índice clave debería ser único. Puedes definir ambos el índice Agrupado y No Agrupado para ser único, siempre que la información en esos índices clave sean únicos.
Un índice Único será creado automáticamente cuando defines una restricción de CLAVE PRIMARIA o CLAVE UNICA en las columnas específicas. En todos los casos, crear un índice Único en la información única, en vez de crear un índice no único en la misma información, es muy recomendable, ya que ayuda al Optimizador de Consultas SQL Server a generar el plan de ejecución más eficiente basado en la información adicional útil provista por el índice.
Asume que necesitamos crear la tabla de abajo, usando la declaración CREATE TABLE T-SQL de abajo, sin especificar ninguna declaración CREATE INDEX, como se muestra abajo:
|
1 2 3 4 5 |
CREATE TABLE DiffIndexTypesDemo ( ID INT IDENTITY (1,1) PRIMARY KEY, Name Varchar(50) CONSTRAINT UQ_Name UNIQUE, ADDRESS NVARCHAR(MAX) ) |
Verás que un índice Único Agrupado será creado automáticamente en la columna ID de esa tabla, para aplicar la restricción PRIMARY KEY, y un índice Único No agrupado será creado automáticamente en la columna Nombre para aplicar la restricción UNIQUE, como se muestra abajo:

Toma en consideración que el índice que es creado automáticamente para aplicar cualquier restricción no puede ser dejado usando una declaración DROP INDEX T-SQL. Si tratamos de dejar el índice Único creado previamente para aplicar la restricción UNIQUE usando la declaración DROP INDEX T-SQL de abajo:
|
1 |
DROP INDEX UQ_Name ON DiffIndexTypesDemo |
La declaración fallará, mostrando que no podemos dejar explícitamente ningún índice que es creado automáticamente para aplicar la restricción, como se muestra en el mensaje de error de abajo:

Para dejar ese índice, deberíamos dejar la restricción que creó el índice, usando la declaración ALTER TABLE…DROP CONSTRAINT T-SQL de abajo:
|
1 |
ALTER TABLE DiffIndexTypesDemo DROP CONSTRAINT UQ_Name |
El Índice Único puede también ser creado manualmente, fuera de la restricción, al especificar la palabra clave UNIQUE en la declaración de creación de índice Agrupado o No Agrupado, como en la declaración CREATE INDEX T-SQL de abajo:
|
1 |
CREATE UNIQUE NONCLUSTERED INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo (NAME) |
La declaración previa CREATE INDEX, puede ser usada para crear un índice Único No Agrupado en la columna Nombre, como se muestra abajo:

Un índice Único es usado para aplicar la singularidad de los valores de índice clave. Por ejemplo, el índice previo es usado para asegurar que ningún valor duplicado para la columna Nombre este disponible en la tabla. Si tratamos de ejecutar la declaración INSERT INTO de abajo que inserta dos nuevos registros con los mismos valores Nombre en la tabla:
|
1 2 |
INSERT INTO DiffIndexTypesDemo VALUES ('John', 'Amman'), ('John', 'Zarqa') |
La declaración fallará, mostrando que no es permitido insertar valores duplicados para el nombre de la columna, que es aplicada por el índice Único creado, proveyendo los valores duplicados evitados, como se muestra en el mensaje de error de abajo:

Si tratamos de dejar el índice Único, usando la declaración INDEX T-SQL de abajo:
|
1 |
DROP INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo |
Luego ejecutas la misma declaración INSERT INTO, verás que los valores duplicados Nombre serán insertados exitosamente, no teniendo restricción o índice que aplica la singularidad de los valores de esa columna, como se muestra claramente abajo:

Ahora, si tratamos de crear el índice Único otra vez en esa tabla, la declaración CREATE INDEX va a fallar, como la tabla ya ha duplicado valores en la columna Nombre como se muestra abajo:

Tampoco usando la operación de creación IGNORE_DUP_KEY funcionará con el índice UNIQUE. Si tratamos de activar esa opción, al crear el índice Único, para ignorar los valores duplicados existentes, la declaración fallará nuevamente mostrando que no podemos crear un índice Único con valores de índice clave duplicados disponibles en la tabla, como se muestra en el mensaje de error de abajo:

Para ser capaz de crear el índice Único en la columna Nombre, deberíamos borrar o actualizar los valores duplicados. En nuestro caso, vamos a actualizar el segundo nombre duplicado usando la declaración UPDATE de abajo:
|
1 2 3 |
SELECT * FROM DiffIndexTypesDemo UPDATE DiffIndexTypesDemo SET Name='Jack' where ID=4 SELECT * FROM DiffIndexTypesDemo |
Con las filas de la table antes y después de la operación UPDATE es mostrada abajo:

Tratando de crear el índice Único después de resolver el problema de duplicado, el índice Único será creado exitosamente como se muestra abajo:

Podemos incluir otra columna en el índice Único clave, para aplicar la singularidad de combinación de las dos columnas, a diferencia de aplicarlo solamente en la columna Nombre. El CREATE INDEX de abajo será usado para crear un índice único que aplica la singularidad de la combinación de columnas ID y Nombre:
|
1 |
CREATE UNIQUE NONCLUSTERED INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo (ID,NAME) |
Si tratamos de correr la declaración de abajo INSERT INTO, que inserta dos registros con el mismo nombre, los registros serán insertados exitosamente, ya que la columna ID es columna IDENTITY que va a asignar diferentes valores por cada fila insertada de la de abajo:

Índice filtrado
Un índice Filtrado es un índice No Agrupado optimizado, introducido en SQL Server 2008, que usa un filtro predicado para mejorar el rendimiento de las consultas que recuperan bien definidos subgrupos de filas de la tabla, al indexar la única porción de las filas de la tabla. El tamaño más pequeño del índice Filtrado, que consume una pequeña cantidad del espacio del disco, comparado con la tamaño de la tabla completa de índice, y mientras más precisas las estadísticas filtradas, que cubren las filas del índice filtrado con solo costo mínimo de mantenimiento, ayuda a mejorar el rendimiento de las consultas al generar una más óptima ejecución del plan.
Un ejemplo de buenos sub-grupos de información, que se pueden beneficiar de las ganancias del rendimiento del índice Filtrado, son las columnas Dispersas con un gran número de valores NULL.
Para más información sobre columnas Dispersas, ver Optimizar el consumo de almacenaje de valores NULL usando Columnas Dispersas SQL Server.
Si tus consultas están recuperando información de las filas NOT NULL, puedes mejorar el rendimiento de las consultas al crear un índice Filtrado que cubre las filas con valores NOT NULL. Otros ejemplos de sub-grupos de información bien definidos, que pueden tomar beneficios del índice Filtrado son las columnas que contienen rangos distintos de valores o información heterogénea categorizada. Para entenderlo prácticamente déjanos quitar la tabla de prueba previamente creada y crear una nueva usando el script T-SQL de abajo:
|
1 2 3 4 5 6 7 8 |
DROP TABLE DiffIndexTypesDemo GO CREATE TABLE DiffIndexTypesDemo ( ID INT IDENTITY (1,1) PRIMARY KEY, Name Varchar(50) , ADDRESS NVARCHAR(MAX) ) GO |
Después de crear la tabla, vamos a llenarla con 10.100 registros, proveyendo solo con 100 valores de valores de columna Nombre y 10 mil filas con valores NULL para esa columna, usando las declaraciones INSERT INTO T-SQL de abajo:
|
1 2 3 4 |
INSERT INTO DiffIndexTypesDemo VALUES ('John', 'Ramtha') GO 100 INSERT INTO DiffIndexTypesDemo VALUES (NULL, 'Zarqa') GO 10000 |
La columna Nombre en la tabla previa puede ser considerada una columna Dispersa, con cerca de 99 % de la información conteniendo valores NULL. Antes de planear crear el índice, deberíamos entender las consultas que están recuperando información de la tabla. Teniendo todas las consultas buscando las filas con valores NOT NULL en las columnas Nombre, después será beneficioso para crear un índice Filtrado en la columna de Nombre, que va a ser más pequeño cuesta menos de mantener ya que contiene menos de 1 % de los valores de la columna, comparado con un índice de tabla llena que contiene todos los valores de la columna Nombre, al proveer un predicado filtrado, como se muestra abajo:
|
1 |
CREATE INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo (Name) WHERE NAME IS NOT NULL |
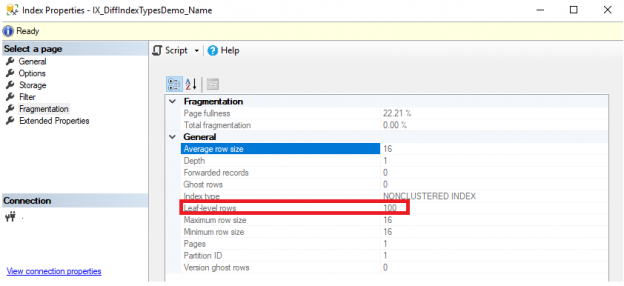
Puedes ver el número de registros incluidos en ese índice de la pestaña de Fragmentación de la ventana de propiedad de índice mostrada abajo:

La consulta siguiente, que recupera los valores NOT NULL de la columna Nombre, va a beneficiarse obviamente del índice Filtrado:
|
1 2 3 4 |
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT Name FROM [dbo].[DiffIndexTypesDemo] WHERE NAME ='John' |
Lo cual es claro de la ejecución del plan generado, en las estadísticas IO y Time de abajo. Verás que el SQL Server va a recuperar la información requerida en poco tiempo al buscar el índice Filtrado como se muestra abajo:

Es recomendado incluir el número más pequeño en las columnas del índice Filtrado que es absolutamente requerido para cubrir la consulta. La columna que es usada en el predicado del índice Filtrado puede ser añadida como columna clave o no-clave en el índice Filtrado si la consulta usa la misma condición usada en el predicado de índice Filtrado y la consulta no retorna la columna con el resultado de la consulta. De otro modo, la columna debería ser añadida como columna clave en el índice Filtrado.
Toma en consideración que la cláusula WHERE del índice Filtrado aceptará solamente operadores de comparaciones simples. Si necesitas una expresión de filtro que referencia tablas múltiples o tiene un predicado complejo, deberías crear una vista.
Para más información sobre vistas de índices, ver Vistas de índices de SQL Server.
Por el otro lado, si un índice Filtrado incluye la mayor parte de las filas de la tabla, es recomendado usar un índice de tabla-entera en vez de un índice Filtrado, ya que el mantenimiento del índice Filtrado será más caro que el índice de tabla-entera en esta situación. La creación del índice Filtrado depende principalmente de tu entendimiento de la información y de las consultas subidas y no será encontradas en las sugestiones de índices perdidos de SQL Server, excepto cuando se usa la herramienta del Asistente Para Optimización de motor de base de datos que puede ayudar en sugerir el índice Filtrado IS NOT NULL.
Índice Espacial
Tipos de información especial de Geometría y Geografía fueron introducidos la primera vez en el SQL Server 2008. El tipo de información de geometría es usado para almacenar información de planificación geométrica como puntos, líneas y polígonos, donde el tipo de información geográfica es usado para representar geográficamente objetos en el área de la superficie de la Tierra, como las coordinadas de latitud y longitud de GPS.
Un índice Espacial es un tipo especial de índice, creado en las columnas que almacenan información espacial, para mejorar el rendimiento de las operaciones realizadas en las columnas espaciales, al reducir el número de objetos en los cuales costosamente las operaciones espaciales necesitan ser aplicadas. Toma en consideración que creando índices Espaciales requiere que la tabla tenga PRIMARY KEY agrupada.
Asume que hemos recreado la tabla previa al cambiar el tipo de información de la columna Address para ser geométricamente espacial, como se muestra abajo:
|
1 2 3 4 5 6 7 8 |
DROP TABLE DiffIndexTypesDemo GO CREATE TABLE DiffIndexTypesDemo ( ID INT IDENTITY (1,1) PRIMARY KEY, Name Varchar(50) , ADDRESS geometry ) GO |
Ahora, podemos crear fácilmente un índice Espacial en la tabla creada, mientras cumple con los dos requerimientos para crear un índice Espacial; hay una columna con tipo de información espacial y un PRIMARY KEY Agrupado en la tabla.
Un índice Espacial puede ser creado en la columna de geometría usando el comando CREATE SPATIAL INDEX T-SQL al proveer el nombre del índice Espacial, el nombre de la tabla en la cual el índice será creado, la columna espacial, el esquema de teselado y la caja de unión.
La declaración CREATE SPATIAL INDEX T-SQL de abajo es usada para crear un índice Espacial en la tabla demo usando el esquema de teselado con una caja de unión específica. La caja de unión son 4 valores tupla numéricos que definen las cuadro coordinadas de la caja de unión: las coordenadas x-min y el y-min de la esquina derecha superior.
|
1 2 3 |
CREATE SPATIAL INDEX SIX_DiffIndexTypesDemo_Address ON DiffIndexTypesDemo(Address) WITH ( BOUNDING_BOX = ( 0, 0, 500, 200 ) ); |
Índices XML
Un índice XML es un tipo especial de índice que es creado en objetos binarios grandes XML (BLOBs) en las columnas de información tipo XML, para mejorar el rendimiento de las consultas que están recuperando información de esa tabla, al indexar todas las etiquetas, valores y direcciones sobre las instancias XML en esa columna.
Hay dos tipos de índices XML: el índice Primario XML y el índice Secundario XML, con la habilidad de crear hasta 249 índices XML en cada tabla. El índice Primario XML es el primer índice Agrupado XML creando en la tabla, con la clave agrupada consiste en la agrupación de la tabla usuario y el nodo identificador XML. Después de crear el índice Primario XML, diferentes tipos de índices Secundarios XML pueden ser creados en la tabla, como el PATH, VALUE y PROPERTY, para mejorar el rendimiento de las consultas subidas, dependiendo del tipo de consultas.
El índice Secundario VALUE XML representa el valor de nodo y camino del índice primario XML. El índice secundario PATH XML construido en los valores de camino y los valores de nodo en los índice primarios XML, permitiendo búsquedas eficientes cuando se busca caminos. El índice Secundario PROPERTY XML contiene la tabla base Primaria Clave, el camino y los valores nodo del índice Primario XML.
Déjanos rediseñar la tabla previa al cambiar la información de la columna tipo Address para ser XML, como se muestra abajo:
|
1 2 3 4 5 6 7 8 |
DROP TABLE DiffIndexTypesDemo GO CREATE TABLE DiffIndexTypesDemo ( ID INT IDENTITY (1,1) PRIMARY KEY, Name Varchar(50) , ADDRESS XML ) GO |
Para mejorar el rendimiento de las consultas que recupera valores XML, vamos a crear un índice Primario XML en la columna Address, usando la declaración CREATE PRIMARY XML INDEX T-SQL de abajo:
|
1 2 3 |
CREATE PRIMARY XML INDEX PXML_DiffIndexTypesDemo_Address ON DiffIndexTypesDemo (Address); GO |
Luego crear un índice XML Secundario PATH en esa columna usando la declaración CREATE XML INDEX T-SQK de abajo:
|
1 2 3 4 |
CREATE XML INDEX ISXML_DiffIndexTypesDemo_Address_Path ON DiffIndexTypesDemo (Address) USING XML INDEX PXML_DiffIndexTypesDemo_Address FOR PATH; GO |
Otros tipos de índices especiales
Índice de Almacenaje en columna:: El índice de almacenaje en columna es una característica en la cual la información será físicamente organizada en un formato de información en columna, no como la tecnología tradicional de almacenamiento en fila, con el formato por fila, que es usado para almacenar, administrar y recuperar grande información usando un formato de información en columna. Un índice de almacenaje en columna funciona bien para cargas de trabajo de almacenaje de información que realiza pesos voluminosos y consultas de solo lectura, llegando a 7x de compresión de la información del tamaño de la información no comprimida.
Para más información sobre índices de almacenaje, véase Cómo Crear un Índice de almacenaje en columna Agrupado en una Tabla de Memoria Optimizada..
Índice de texto entero: : Este es un tipo especial de índice con base funcional token, que es construido y mantenido por el Motor SQL Server Texto Entero, para mejorar el rendimiento de la búsqueda de cadena de caracteres de información. Para más información sobre la búsqueda de Texto Entero, véase Población de Índices Texto Entero.
Índice Hash: Este es un tipo especial de índice usado en tablas de Memoria Optimizada, para acceder a la información a través de una tabla in-memory hash, consumiendo una cantidad fija de memoria, especificada por la cuenta.
Para más información sobre tablas de Memoria Optimizada, véase Mejoramientos de In-Memory OLTP en SQL Server 2016..
Mantente sintonizado para el siguiente artículo, en el cual vamos a discutir cómo mejorar el rendimiento de las consultas al usar el tipo apropiado de índice.
Tabla de contenido
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.



He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019